
 نویسنده : مرتضی حاجی آبادی
نویسنده : مرتضی حاجی آبادی برای شروع حرفهای کنکور ارشد کامپیوتر،آیتی و علوم کامپیوتر حتما روی عکس زیر کلیک کنید تا در کانال کنکور کامپیوتر عضو شوید، در این کانال به معرفی بهترین منابع کنکور ارشد،برنامه ریزی و مشاوره، معرفی گرایشها و هر آنچه برای موفقیت در کنکور ارشد نیاز دارید پرداخته شده است

سلام به همه شما علاقه مندان عزیز به الگوریتم ژنتیک، به کاملترین صفحهای که برای معرفی و بررسی الگوریتم ژنتیک در وب فارسی وجود داره خوش اومدید 😉
الگوریتم های ژنتیک نوعی الگوریتم بهینه سازی هستند، به این معنی که برای یافتن حداکثر یا حداقل یک تابع استفاده می شوند. در این مقاله ما الگوریتم های ژنتیک را نشان داده و مورد بحث قرار می دهیم. ما نشان می دهیم که چه اجزایی الگوریتم های ژنتیک را تشکیل می دهند و چگونه آنها را بنویسیم. ما همچنین تاریخچه الگوریتم های ژنتیک، کاربردهای فعلی و پیشرفت های آینده را مورد بحث قرار می دهیم. الگوریتمهای ژنتیک نشاندهنده یکی از شاخههای مطالعاتی به نام محاسبات تکاملی هستند که از فرآیندهای بیولوژیکی تولید مثل و انتخاب طبیعی برای حل «مناسبترین» راهحلها تقلید میکنند.

مانند تکامل، بسیاری از فرآیندهای الگوریتم ژنتیک تصادفی هستند، اما این تکنیک بهینهسازی به فرد اجازه میدهد تا سطح تصادفیسازی و سطح کنترل را تعیین کند.
این الگوریتمها بسیار قویتر و کارآمدتر از جستجوی تصادفی و الگوریتمهای جستجوی جامع هستند، در عین حال نیازی به اطلاعات اضافی در مورد مسئله ندارند. این ویژگی به آنها اجازه میدهد تا راهحلهایی برای مشکلاتی بیابند که سایر روشهای بهینهسازی به دلیل عدم تداوم، مشتقات، خطی بودن یا ویژگیهای دیگر نمیتوانند از عهده آن برآیند. همچنین برای مطالعه بیشتر در مورد اینکه بطورکلی الگوریتم چیست و آشنایی با انواع الگوریتمالگوریتم چیست به زبان ساده و با مثال های فراوان در این مقاله به زبان بسیار ساده و با مثال های متعدد توضیح داده شده که الگوریتم چیست و چه کاربردهایی دارد ها به صفحه مذکور مراجعه کنید، همچنین برای آشنایی و یادگیری طراحی الگوریتم و ساختمان داده میتوانید به صفحه ساختمان دادهآموزش ساختمان داده و الگوریتم
در این مقاله به زبان بسیار ساده و با مثال های متعدد توضیح داده شده که الگوریتم چیست و چه کاربردهایی دارد ها به صفحه مذکور مراجعه کنید، همچنین برای آشنایی و یادگیری طراحی الگوریتم و ساختمان داده میتوانید به صفحه ساختمان دادهآموزش ساختمان داده و الگوریتم هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است و طراحی الگوریتمآموزش طراحی الگوریتم به زبان ساده
هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است و طراحی الگوریتمآموزش طراحی الگوریتم به زبان ساده درس طراحی الگوریتم یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است. هدف از این درس، معرفی روشهای مختلف طراحی الگوریتمها برای حل مسائل گوناگون است، در این صفحه به معرفی و آموزش طراحی الگوریتم پرداخته شده است. مراجعه فرمائید.
درس طراحی الگوریتم یکی از مهمترین و بنیادیترین دروس رشته کامپیوتر است. هدف از این درس، معرفی روشهای مختلف طراحی الگوریتمها برای حل مسائل گوناگون است، در این صفحه به معرفی و آموزش طراحی الگوریتم پرداخته شده است. مراجعه فرمائید.
تاریخچه الگوریتم های ژنتیک
محاسبات تکاملی در دهه ۱۹۶۰ توسط اینگو رِشِنبرگ معرفی شد. جان هالند در سال ۱۹۷۵ اولین کتاب در مورد الگوریتم های ژنتیک را با عنوان انطباق در سیستم های طبیعی و مصنوعی نوشت. در سال ۱۹۹۲ جان کوزا از الگوریتم ژنتیک برای تکامل برنامه ها برای انجام وظایف خاص استفاده کرد. او روش خود را برنامه ریزی ژنتیکی نامید.

اصطلاحات طبیعت و معادل کامپیوتری آن ها
| کامپیوتر | طبیعت |
|---|---|
| مجموعه ای از راه حل ها | جمعیت |
| راه حلی برای یک مسئله | فرد |
| کیفیت یک راه حل | برازندگی |
| رمزگذاری برای یک راه حل | کروموزوم |
| بخشی از رمزگذاری برای یک راه حل | ژن |
| ترکیب | تولید مثل |
مولفه ها، ساختار و اصطلاحات
از آنجایی که الگوریتم های ژنتیک برای شبیه سازی یک فرآیند بیولوژیکی طراحی شده اند، بسیاری از اصطلاحات مربوطه از زیست شناسی به عاریت گرفته شده است. با این حال، موجوداتی که این اصطلاح در الگوریتم های ژنتیک به آنها اشاره می کند بسیار ساده تر از همتایان بیولوژیکی خود هستند. اجزای اساسی مشترک تقریباً همه الگوریتم های ژنتیک عبارتند از:
- یک تابع برازندگی (Fitness Function) برای بهینه سازی
- جمعیتی از کروموزوم ها (Chromosomes)
- انتخاب (Selection) کروموزوم هایی که تکثیر خواهند شد
- ترکیب (Crossover) برای تولید نسل (Generation) بعدی کروموزوم ها
- جهش (Mutation) تصادفی کروموزوم ها در نسل جدید
تابع برازندگی تابعی است که الگوریتم سعی در بهینه سازی آن دارد. واژه برازندگی که از نظریه تکاملی گرفته شده است در اینجا استفاده می شود زیرا تابع برازندگی هر راه حل بالقوه را آزمایش و کیفیت آن را مشخص می کند. تابع برازندگی یکی از محوری ترین بخش های الگوریتم است.

واژه کروموزوم به یک مقدار یا مقادیر عددی اشاره دارد که نشان دهنده یک راه حل کاندیدا برای مسئله ای است که الگوریتم ژنتیک سعی در حل آن دارد. هر راه حل کاندیدا به عنوان آرایه ای از مقادیر پارامتر کدگذاری می شود، فرآیندی که در سایر الگوریتم های بهینه سازی نیز یافت می شود. اگر یک مسئله دارای ابعاد Npar باشد، معمولاً هر کروموزوم به عنوان یک آرایه با Npar عضو مانند chromosome = [p1,p2,…,pNpar] کدگذاری میشود که در آن هر pi مقدار خاصی از پارامتر i امین است. این به استفاده کننده الگوریتم ژنتیک بستگی دارد که چگونه فضای نمونه راه حل های کاندیدا را به کروموزوم ترجمه کند.
یک رویکرد این است که هر مقدار پارامتر را به یک رشته بیت (توالی 1 و 0) تبدیل کنید، سپس پارامترها را مانند ژنها از سر به انتها در یک رشته DNA برای ایجاد کروموزومها الحاق کنید. از نظر تاریخی، کروموزومها معمولاً به این روش کدگذاری میشدند، و این روشی مناسب برای فضاهای راه حل گسسته بود. رایانههای مدرن به کروموزومها اجازه میدهند که جایگشت، اعداد واقعی و بسیاری از اجسام دیگر را شامل شوند. اما در حال حاضر ما بر روی کروموزوم های دوتایی تمرکز خواهیم کرد. یک الگوریتم ژنتیک با مجموعهای از کروموزومها که بهطور تصادفی انتخاب شدهاند، آغاز میشود که به عنوان نسل اول (جمعیت اولیه) عمل میکند.
سپس هر کروموزوم در جمعیت توسط تابع برازندگی ارزیابی می شود تا آزمایش شود که چگونه مشکل موجود را حل می کند. اکنون عملگر انتخاب برخی از کروموزوم ها را برای تولید مثل بر اساس توزیع احتمالی که کاربر تعریف می کند انتخاب می کند. هر چه کروموزوم مناسب تر باشد، احتمال انتخاب آن بیشتر است. برای مثال، اگر f یک تابع برازندگی غیر منفی باشد، احتمال اینکه کروموزوم C53 برای تولید مثل انتخاب شود برابر است با:

توجه داشته باشید که عملگر انتخاب کروموزوم ها را با جایگزینی انتخاب می کند، بنابراین یک کروموزوم می تواند بیش از یک بار انتخاب شود. عملگر ترکیب شبیه ترکیب بیولوژیکی و ترکیب مجدد کروموزوم ها در میوز سلولی است. این عملگر دنباله ای از دو کروموزوم انتخابی را برای ایجاد دو فرزند تعویض می کند. به عنوان مثال، اگر کروموزوم های والد [11010111001000] و [01011101010010]، پس از بیت چهارم ترکیب شوند، [01010111001000] و [11011101010010] فرزندان آنها خواهند بود. عملگر جهش به طور تصادفی تک تک بیت ها را در کروموزوم های جدید ورق می زند (تبدیل 0 به 1 و بالعکس). به طور معمول جهش با احتمال بسیار کم مانند 0.001 اتفاق می افتد. برخی از الگوریتمها عملگر جهش را قبل از عملگرهای انتخاب و ترکیب پیادهسازی میکنند.
این یک موضوع ترجیحی است. در نگاه اول، عملگر جهش ممکن است غیر ضروری به نظر برسد. ولی در واقع، نقش مهمی را ایفا می کند، حتی اگر در درجه دوم از انتخاب و ترکیب باشد. انتخاب و ترکیب اطلاعات ژنتیکی کروموزومهای مناسبتر را حفظ میکند، اما این کروموزومها فقط نسبت به نسل فعلی مناسبتر هستند. این می تواند باعث شود که الگوریتم خیلی سریع همگرا شود و مواد ژنتیکی بالقوه مفید (1 یا 0 در مکان های خاص) را از دست بدهد. به عبارت دیگر، الگوریتم می تواند قبل از یافتن بهینه جهانی در یک بهینه محلی گیر کند. عملگر جهش با حفظ تنوع در جمعیت به محافظت در برابر این مشکل کمک می کند، اما همچنین می تواند باعث شود الگوریتم به کندی همگرا شود.
با این حال، برخی از الگوریتمها به اعضای بسیار مناسب نسل اول اجازه میدهند تا در نسل دوم زنده بمانند. اکنون نسل دوم با عملکرد تابع برازندگی آزمایش می شود و چرخه تکرار می شود. ثبت کروموزوم با بالاترین برازندگی (همراه با ارزش برازندگی آن) از هر نسل یا کروموزوم بهترین تاکنون(best-so-far) یک روش معمول است. الگوریتم های ژنتیک تا زمانی تکرار می شوند که ارزش برازندگی کروموزوم بهترین تاکنون تثبیت شود و برای چندین نسل تغییر نکند. این بدان معناست که الگوریتم به یک راه حل (های) همگرا شده است. کل فرآیند تکرارها را اجرا(run) می گویند. در پایان هر مرحله معمولاً حداقل یک کروموزوم وجود دارد که راه حل بسیار مناسبی برای مشکل اصلی است.
بسته به نحوه نگارش الگوریتم، این میتواند مناسبترین کروموزومهای بهترین تاکنون یا بیشترین برازندگی در نسل نهایی باشد. عملکرد یک الگوریتم ژنتیک به شدت به روش مورد استفاده برای رمزگذاری راه حل های کاندیدا در کروموزوم ها و معیار خاص موفقیت یا آنچه که تابع برازندگی در واقع اندازه گیری می کند بستگی دارد. سایر جزئیات مهم احتمال ترکیب، احتمال جهش، اندازه جمعیت و تعداد تکرارها هستند. این مقادیر را می توان پس از ارزیابی عملکرد الگوریتم در چند دوره آزمایشی تنظیم کرد. الگوریتم های ژنتیک در کاربردهای مختلفی مورد استفاده قرار می گیرند. برخی از نمونه های برجسته برنامه نویسی خودکار و یادگیری ماشین هستند. آنها همچنین برای مدلسازی پدیدههای اقتصاد، اکولوژی، سیستم ایمنی انسان، ژنتیک جمعیت و سیستمهای اجتماعی مناسب هستند.
یک الگوریتم ژنتیک ساده
با توجه به یک مسئله به وضوح تعریف شده که باید حل شود و یک نمایش رشته بیتی برای راه حل های کاندیدا، یک الگوریتم ژنتیک ساده به صورت زیر عمل می کند:
- با جمعیتی از کروموزومهای nبیتی که بهطور تصادفی تولید میشوند (راهحلهای نامزد برای یک مسئله) شروع کنید.
- تابع برازندگی f(x) هر کروموزوم xدر جمعیت را محاسبه کنید.
- مراحل زیر را تکرار کنید تا n فرزند ایجاد شود:
- یک جفت کروموزوم والد را از جمعیت فعلی انتخاب کنید، که احتمال انتخاب تابعی از برازندگی است. انتخاب با جایگزینی انجام می شود، به این معنی که همان کروموزوم را می توان بیش از یک بار برای تبدیل شدن به والد انتخاب کرد.
- با احتمال pc ("احتمال ترکیب" یا "نرخ ترکیب")، جفت را در یک نقطه به طور تصادفی انتخاب شده (انتخاب شده با احتمال یکسان) ترکیب کنید تا دو فرزند تشکیل شود. اگر تلاقی صورت نگرفت، دو فرزند تشکیل دهید که کپی دقیقی از والدین مربوطه خود هستند. (توجه داشته باشید که در اینجا نرخ ترکیب به عنوان احتمال ترکیب والدین در یک نقطه تعریف میشود. همچنین نسخههای ترکیب چند نقطهای از الگوریتم ژنتیک وجود دارد که در آن نرخ ترکیب برای والدین عدد نقاطی است که در آن یک تلاقی اتفاق می افتد.)
- دو فرزند را در هر مکان با احتمال pm (احتمال جهش یا نرخ جهش) جهش دهید و کروموزوم های حاصل را در جمعیت جدید قرار دهید. اگر n فرد باشد، یک عضو جدید جمعیت را می توان به طور تصادفی کنار گذاشت.
- جمعیت فعلی را با جمعیت جدید جایگزین کنید.
- به مرحله 2 بروید.
Simple_Genetic_Algorithm() {
Initialize the Population;
Calculate Fitness Function;
While(Fitness Value != Optimal Value) {
Selection;
Crossover;
Mutation;
Calculate Fitness Function;
}
}

هر تکرار از این فرآیند یک نسل نامیده می شود. یک الگوریتم ژنتیک معمولاً برای هر جایی از ۵۰ تا ۵۰۰ یا نسل های بیشتر تکرار می شود. کل مجموعه نسل ها را اجرا (run) می گویند. در پایان یک اجرا اغلب یک یا چند کروموزوم بسیار برازنده در جمعیت وجود دارد. از آنجایی که تصادفی بودن نقش بزرگی در هر اجرا ایفا میکند، دو اجرا با تعداد دانه(seed)های تصادفی متفاوت معمولاً رفتارهای دقیقا متفاوتی ایجاد میکنند. محققان الگوریتم ژنتیک اغلب آماری (مانند بهترین برازندگی یافت شده در یک اجرا و نسلی که در آن فرد با بهترین برازندگی کشف شد) که میانگین تعداد زیادی از اجرا های مختلف الگوریتم ژنتیک است را در مورد یک مسئله را گزارش می کنند.
رویه ساده ای که توضیح داده شد، اساس اکثر کاربردهای الگوریتم ژنتیک است. تعدادی جزئیات برای بیان کردن وجود دارد، مانند اندازه جمعیت و احتمالات ترکیب و جهش، و موفقیت الگوریتم اغلب به این جزئیات بستگی دارد. همچنین نسخههای پیچیدهتری از الگوریتم ژنتیک وجود دارد (به عنوان مثال، الگوریتم های ژنتیکی که روی نمایشهایی غیر از رشتهها کار میکنند یا الگوریتم های ژنتیکی که دارای انواع مختلف عملگرهای ترکیب و جهش هستند).
به عنوان یک مثال دقیق تر از یک الگوریتم ژنتیک ساده، فرض کنید L (طول رشته) ۸ است،f(x) برابر است با تعداد یک ها در رشته بیتی x (یک تابع برازندگی بسیار ساده، که در اینجا فقط برای مقاصد توضیحی استفاده می شود)است ، n (اندازه جمعیت) ۴ است، pc= ۰.۷، و آن pm= ۰.۰۰۱ است. (مانند تابع برازندگی، این مقادیر L و n برای سادگی انتخاب شدند. مقادیر معمولی بیشتر L و n در محدوده ۵۰-۱۰۰۰ هستند. مقادیر داده شده برای pc و pm نسبتاً معمولی هستند.)
جمعیت اولیه (به طور تصادفی تولید شده) ممکن است به شکل زیر باشد:
| Fitness | Chromosome string | Chromosome label |
|---|---|---|
| 2 | 00000110 | A |
| 6 | 11101110 | B |
| 1 | 00100000 | C |
| 3 | 00110100 | D |
یک روش انتخاب متداول در الگوریتم های ژنتیک انتخاب متناسب با تابع برازندگی است که در آن تعداد دفعاتی که از یک فرد انتظار می رود تولید مثل کند برابر است با برازندگی آن تقسیم بر میانگین برازندگی در جمعیت. -این معادل چیزی است که زیست شناسان آن را انتخاب قابلیت حیات(viability selection) می نامند.
یک روش ساده برای اجرای انتخاب متناسب با تابع برازندگی، نمونه برداری از چرخ رولت است (گلدبرگ ۱۹۸۹)، که از نظر مفهومی معادل دادن یک تکه از چرخ رولت دایره ای به هر فرد است که مساحتی برابر با برازندگی فرد دارد. چرخ رولت میچرخد، توپ روی یک تکه گوه ای شکل قرار می گیرد و فرد مربوطه انتخاب می شود. در مثال n = ۴ بالا، چرخ رولت چهار بار می چرخد. دو چرخش اول ممکن است کروموزوم های B و D را به عنوان والدین انتخاب کنند و دو چرخش دوم ممکن است کروموزوم های B و C را به عنوان والدین انتخاب کنند. (این واقعیت که ممکن است A انتخاب نشود فقط شانس قرعه کشی است. اگر چرخ رولت بارها بچرخد، میانگین نتایج به مقادیر مورد انتظار نزدیکتر خواهد بود.)
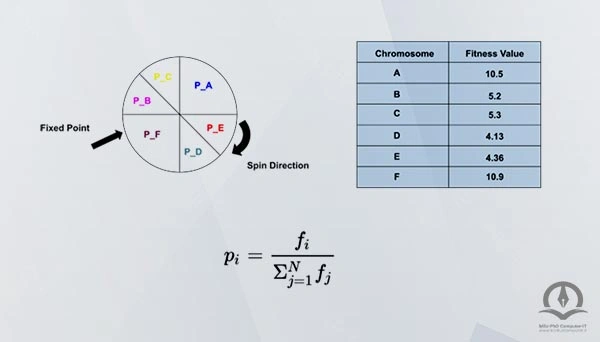
هنگامی که یک جفت از والدین انتخاب میشوند، با احتمال pc از ترکیب می کنند تا دو فرزند تشکیل دهند. اگر آنها ترکیب نشوند، فرزندان نسخههای دقیقی از هر یک از والدین هستند. فرض کنید، در مثال بالا، والدین B و D پس از اولین موقعیت بیت با یکدیگر ترکیب شوند تا فرزندان E = 10110100 و F = 01101110 را تشکیل دهند، و والدین B و C با هم ترکیب نمی شوند، در عوض فرزندانی را تشکیل می دهند که کپی دقیقی از B و C هستند. سپس، هر فرزند در معرض جهش در هر مکان با احتمال pm است. به عنوان مثال، فرض کنید فرزندان E در جایگاه ششم جهش یافته اند تا E' = 10110000، فرزندان F و C به هیچ وجه جهش نداشته باشند و فرزندان B در جایگاه اول جهش یافته و B' = 01101110 را تشکیل دهند. جمعیت جدید به شرح زیر خواهد بود:
| Fitness | Chromosome String | Chromosome Label |
|---|---|---|
| 3 | 1011000 | E’ |
| 5 | 01101110 | F |
| 1 | 00100000 | C |
| 5 | 01101110 | B’ |
توجه داشته باشید که در جمعیت جدید، اگرچه بهترین رشته (رشته با برازندگی ۶) از بین رفت، اما میانگین برازندگی از ۱۲.۴ به ۱۴.۴ افزایش یافت. تکرار این رویه در نهایت منجر به یک رشته می شود که همه بیت هایش ۱ باشد.
چه زمانی باید از الگوریتم ژنتیک استفاده کرد؟
ادبیات الگوریتم ژنتیک تعداد زیادی از برنامه های کاربردی موفق را توصیف می کند، اما موارد بسیاری نیز وجود دارد که در آنها الگوریتم های ژنتیک عملکرد ضعیفی دارند. با توجه به یک کاربرد بالقوه خاص، چگونه بفهمیم که الگوریتم ژنتیک روش خوبی برای استفاده کردن است؟ هیچ پاسخ دقیقی وجود ندارد، اگرچه بسیاری از محققان این تصور را دارند که اگر فضای مورد جستجو بزرگ باشد، کاملاً صاف(smooth) و تک وجهی(unimodal) نیست (یعنی از یک تپه صاف تشکیل شده است) یا به خوبی درک نشده است. یا اگر عملکرد تابع برازندگی نویزی باشد، و اگر کار نیازی به یافتن بهینه جهانی نداشته باشد - یعنی اگر یافتن سریع یک راه حل به اندازه کافی خوب، کافی است - یک الگوریتم ژنتیک شانس خوبی برای رقابت با سایر روش های ضعیف یا پیشی گرفتن از آنها خواهد داشت(روشهایی که از دانش خاص دامنه در روند جستجوی خود استفاده نمیکنند).
اگر یک فضا بزرگ نباشد، میتوان آن را به طور کامل جستجو کرد و می توان مطمئن بود که بهترین راه حل ممکن پیدا شده است، در حالی که یک الگوریتم ژنتیک ممکن است به جای بهترین راه حل جهانی، روی یک بهینه محلی همگرا شود. اگر فضا صاف (smooth) یا تک وجهی (unimodal) باشد، یک الگوریتم شیب صعود مانند تپه نوردی با شیب تند، بسیار کارآمدتر از الگوریتم ژنتیک در بهره برداری از صافی فضا خواهد بود. اگر فضا به خوبی درک شده باشد (مثلاً مانند فضای مسئله معروف فروشنده مسافرتی(traveling salesman))، روشهای جستجو با استفاده از اکتشافات دامنه خاص اغلب میتوانند به گونهای طراحی شوند که از هر روش همه منظوره مانند الگوریتم ژنتیک بهتر عمل کنند. اگر عملکرد تابع برازندگی نویزی باشد (به عنوان مثال، اگر شامل اندازه گیری های مستعد خطا از یک فرآیند واقعی مانند سیستم بینایی یک ربات باشد)، یک روش جستجوی یک راه حل در یک زمان(one−candidate−solution−at−a−time)، مانند تپه نوردی ساده ممکن است به طور غیر قابل جبرانی توسط نویز به بیراهه کشیده شود، اما الگوریتم های ژنتیک، از آنجایی که آنها با جمع آوری آمار برازندگی در طول نسل ها کار می کنند، تصور می شود که در حضور مقادیر کمی نویز عملکرد قوی دارند.
البته این شهودها به طور دقیق پیشبینی نمیکنند که چه زمانی یک الگوریتم ژنتیک یک روش جستجوی مؤثر در رقابت با سایر روش ها خواهد بود. عملکرد یک الگوریتم ژنتیک بسیار به جزئیاتی مانند روش رمزگذاری راه حل های کاندیدا، عملگرها، تنظیمات پارامترها و معیارهای خاص برای موفقیت بستگی دارد.
عملگرها و پارامترهای الگوریتم ژنتیک
- رمزگذاری (Encoding) : رمزگذاری فرآیندی برای نمایش راه حل در قالب یک رشته است که اطلاعات لازم را منتقل می کند. همانطور که در یک کروموزوم، هر ژن یک ویژگی خاص از فرد را کنترل می کند، به طور مشابه، هر بیت در رشته نشان دهنده یک ویژگی راه حل است.
- رمزگذاری دودویی (Binary Encoding) : رمزگذاری دودویی رایج ترین روش رمزگذاری است. کروموزوم ها رشته های 1 و 0 هستند و هر موقعیت در کروموزوم نشان دهنده ویژگی خاصی از مسئله است.
- رمزگذاری جایگشت (Permutation Encoding) : برای مسائلی مانند مسئله فروشنده دوره گرد (TSP) مفید است. در فروشنده دوره گرد هر کروموزوم رشته ای از اعداد است که هر کدام نشان دهنده شهری است که باید بازدید کرد.
- رمزگذاری ارزش (Value Encoding) : در مسائلی که از مقادیر پیچیده مانند اعداد واقعی استفاده میشود و کدگذاری دودویی کافی نیست استفاده میشود. برای برخی مشکلات خوب است، اما اغلب برای ایجاد برخی تکنیک های ترکیب و جهش خاص برای این کروموزوم ها ضروری است.
- تابع برازندگی : یک تابع برازندگی، بهینه بودن یک راه حل (کروموزوم) را کمی می کند، به طوری که آن راه حل خاص ممکن است در برابر همه راه حل های دیگر رتبه بندی شود. یک مقدار برازندگی به هر راه حل بسته به اینکه واقعاً چقدر به حل مسئله نزدیک است، اختصاص داده می شود. عملکرد تابع برازندگی ایده آل ارتباط نزدیکی با هدف دارد و به سرعت قابل محاسبه است. در TSP، تابعf(x) مجموع فواصل بین شهرها در راه حل است. هر چه مقدار کمتر باشد، راه حل مناسب تر است.
- انتخاب : انتخاب فرآیندی است که تعیین میکند کدام راهحلها باید حفظ شوند و اجازه تولید مجدد داده شود و کدام یک مستحق نابودی هستند. هدف اصلی عملگر انتخاب تاکید بر راه حل های خوب و حذف راه حل های بد در یک جمعیت است، در حالی که اندازه جمعیت را ثابت نگه می دارد. بهترین ها را انتخاب می کند، بقیه را کنار می گذارد. راه حل های خوب را در یک جمعیت شناسایی میکند. چندین کپی از راه حل های خوب تهیه میکند. راه حل های بد را از جمعیت حذف میکند تا بتوان چندین نسخه از راه حل های خوب را در جمعیت قرار داد.
- ترکیب : ترکیب فرآیندی است که در آن دو کروموزوم (رشتهها) مواد ژنتیکی (بیتها) خود را با هم ترکیب میکنند تا فرزندان جدیدی تولید کنند که هر دو ویژگی آنها را دارند. دو رشته از استخر(pool) جفت گیری به طور تصادفی برای ترکیب از آن انتخاب می شود. روش انتخاب شده به روش رمزگذاری بستگی دارد.
- ترکیب تک نقطه ای : یک نقطه تصادفی روی هر کروموزوم (رشته) انتخاب می شود و ماده ژنتیکی در این نقطه مبادله می شود.
- ترکیب دو نقطه ای : دو نقطه تصادفی روی هر کروموزوم (رشته) انتخاب می شود و ماده ژنتیکی در این نقاط رد و بدل می شود.
- ترکیب یکنواخت : هر ژن (بیت) به طور تصادفی از یکی از ژن های مربوط به کروموزوم های والد انتخاب می شود. ترکیب یکنواخت فقط 1 فرزند تولید می کند.
- جهش : جهش فرآیندی است که طی آن یک رشته به طور عمدی تغییر میکند تا تنوع در مجموعه جمعیت حفظ شود. احتمال جهش تعیین می کند که هر چند وقت یکبار قسمت های کروموزوم جهش می یابند. برای کروموزوم هایی که از رمزگذاری دودویی استفاده می کنند، بیت های انتخاب شده به طور تصادفی معکوس می شوند.
روش های رمزگذاری:
| 10110010110011100101 | Chromosome A |
| 11111110000000011111 | Chromosome B |
| 8 9 7 4 6 2 3 5 1 | Chromosome A |
| 9 4 1 3 2 7 6 5 8 | Chromosome B |
| 2.454 2.321 0.454 5.323 1.235 | Chromosome A |
| (left) , (back) , (left) , (right) , (forward) | Chromosome B |


روش های ترکیب :
| 00100110110 | 11011 | Chromosome1 |
| 11000011110 | 11011 | Chromosome2 |
| 11000011110 | 11011 | Offspring1 |
| 00100110110 | 11011 | Offspring2 |
| 110110| 00100 | 11011 | Chromosome1 |
| 011110| 11000 | 10101 | Chromosome2 |
| 011110| 00100 | 10101 | Offspring1 |
| 110110| 11000 | 11011 | Offspring2 |
| 110110| 00100 | 11011 | Chromosome1 |
| 011110| 11000 | 10101 | Chromosome2 |
| 110110| 00000 | 10111 | Offspring1 |
110110 0010 110110 | Offspring |
100110 00100 11010 | Mutated Offspring |
تعداد بیت هایی که باید معکوس شوند به احتمال جهش بستگی دارد.
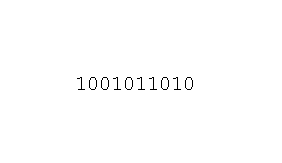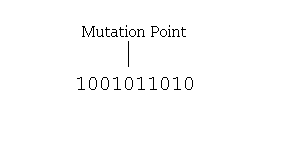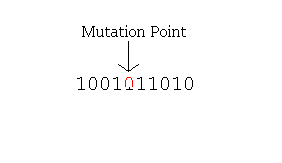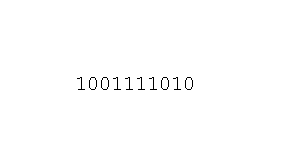
حل مسئله 8 وزیر با الگوریتم ژنتیک
در سال ۱۸۴۸، یک شطرنج باز آلمانی به نام مکس بززل(Max Bezzel) مسئله 8 وزیر را ساخت که هدف آن قرار دادن ۸ وزیر در صفحه شطرنج به گونه ای است که هیچ دو وزیر نتوانند به یکدیگر حمله کنند. در سال ۱۸۵۰ فرانتس ناوک(Franz Nauck) اولین راه حل را برای این مسئله ارائه کرد و مسئله را به مسئله N-Queen برای N وزیر غیر مهاجم در صفحه شطرنج N x N تعمیم داد. پیچیدگی زمانی یک مسئله N وزیر، O(n!) است.
برای حل این مسئله ما هر راه حل را به صورت یک رشته ۸ بیتی در نظر میگیریم.

تابع برازندگی : تعداد جفت وزیری است که همدیگر را تهدید نمیکنند. برای تصویر بالا این مقدار برابر است با ۲۴.
ترکیب : انتخاب بخشی از حالت از یک والدین و بقیه از دیگری.
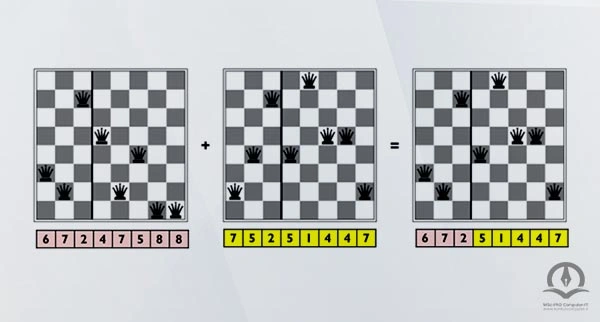
جهش : تغییر قسمت کوچکی از یک حالت با احتمال کم.
به طور مثال برای گونه ای از این مسئله کروموزوم های زیر را داریم:
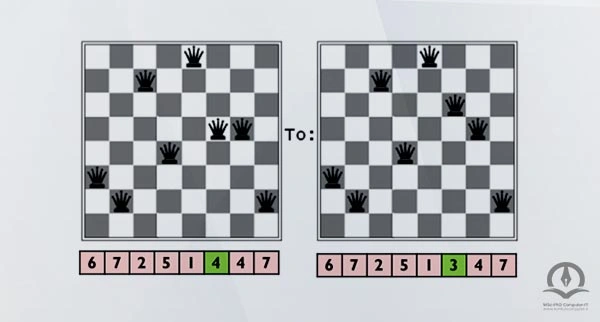
در زیر کل فرایند از جمعیت اولیه تا محاسبه تابع برازندگی، تا انتخاب تا ترکیب و در نهایت جهش را نشان می دهد. جهش ممکن است رخ دهد یا ندهد.

الگوریتم ژنتیک با پایتون
#Constants, experiment parameters
NUM_QUEENS = 8
POPULATION_SIZE = 10
MIXING_NUMBER = 2
MUTATION_RATE = 0.05
def fitness_score(seq):
score = 0
for row in range(NUM_QUEENS):
col = seq[row]
for other_row in range(NUM_QUEENS):
#queens cannot pair with itself
if other_row == row:
continue
if seq[other_row] == col:
continue
if other_row + seq[other_row] == row + col:
continue
if other_row - seq[other_row] == row - col:
continue
#score++ if every pair of queens are non-attacking.
score += 1
#divide by 2 as pairs of queens are commutative
return score/2
import random
from scipy import special as sc
def selection(population):
parents = []
for ind in population:
#select parents with probability proportional to their fitness score
if random.randrange(sc.comb(NUM_QUEENS, 2)*2) < fitness_score(ind):
parents.append(ind)
return parents
import itertools
def crossover(parents):
#random indexes to to cross states with
cross_points = random.sample(range(NUM_QUEENS), MIXING_NUMBER - 1)
offsprings = []
#all permutations of parents
permutations = list(itertools.permutations(parents, MIXING_NUMBER))
for perm in permutations:
offspring = []
#track starting index of sublist
start_pt = 0
for parent_idx, cross_point in enumerate(cross_points): #doesn't account for last parent
#sublist of parent to be crossed
parent_part = perm[parent_idx][start_pt:cross_point]
offspring.append(parent_part)
#update index pointer
start_pt = cross_point
#last parent
last_parent = perm[-1]
parent_part = last_parent[cross_point:]
offspring.append(parent_part)
#flatten the list since append works kinda differently
offsprings.append(list(itertools.chain(*offspring)))
return offsprings
def mutate(seq):
for row in range(len(seq)):
if random.random() < MUTATION_RATE:
seq[row] = random.randrange(NUM_QUEENS)
return seq
def print_found_goal(population, to_print=True):
for ind in population:
score = fitness_score(ind)
if to_print:
print(f'{ind}. Score: {score}')
if score == sc.comb(NUM_QUEENS, 2):
if to_print:
print('Solution found')
return True
if to_print:
print('Solution not found')
return False
def evolution(population):
#select individuals to become parents
parents = selection(population)
#recombination. Create new offsprings
offsprings = crossover(parents)
#mutation
offsprings = list(map(mutate, offsprings))
#introduce top-scoring individuals from previous generation and keep top fitness individuals
new_gen = offsprings
for ind in population:
new_gen.append(ind)
new_gen = sorted(new_gen, key=lambda ind: fitness_score(ind), reverse=True)[:POPULATION_SIZE]
return new_gen
def generate_population():
population = []
for individual in range(POPULATION_SIZE):
new = [random.randrange(NUM_QUEENS) for idx in range(NUM_QUEENS)]
population.append(new)
return population
#Running the experiment
generation = 0
#generate random population
population = generate_population()
while not print_found_goal(population):
print(f'Generation: {generation}')
print_found_goal(population)
population = evolution(population)
generation += 1
پیاده سازی الگوریتم ژنتیک در متلب
تابع ترکیب :
function children = crossover(parents)
% Crossover Function
children = zeros(2,8);
p = randi([2, 7]);
children(1,1:p) = parents(1,1:p);
children(2,1:p) = parents(2,1:p);
idx = p+1;
for i = p+1:8
if ismember(parents(2,i),children(1,1:p))==0
children(1,idx) = parents(2,i);
idx = idx + 1;
end
end
for i = 1:p
if ismember(children(2,i),children(1,1:p))==0
children(1,idx) = children(2,i);
idx = idx + 1;
end
end
idx = p+1;
for i = p+1:8
if ismember(parents(1,i),children(2,1:p))==0
children(2,idx) = parents(1,i);
idx = idx + 1;
end
end
for i = 1:p
if ismember(children(1,i),children(2,1:p))==0
children(2,idx) = children(1,i);
idx = idx + 1;
end
end
end
تابع برازندگی :
function out = fitness(chromosome)
% This function returns fitness which equals by the number of gaurds
% Transform the input chromosome into the chess field
field = zeros(8,8);
for i = 1:8
field(chromosome(i),i) = 1;
end
% Counting number of gaurds
temp = zeros(8,8);
for i = 1:8
temp(i,:) = field(:,8+1-i);
end
out = 0;
for i = -7:7
res1 = sum(diag(field,i));
res2 = sum(diag(temp,i));
if res1 > 1
out = out + res1;
end
if res2 > 1
out = out + res2;
end
end
end
تابع جهش :
function children = mutation(chroms)
% Mutation Function
for i = 1:2
a = randi([1, 8]);
b = randi([1, 8]);
tmp = chroms(i,a);
chroms(i,a) = chroms(i,b);
chroms(i,b) = tmp;
end
children = chroms;
end
تابع انتخاب :
function selected = parent_selection(population,N,K)
% This function returns the selected parents
all_selected = population(randperm(8,N),:);
fits = zeros(1,N);
for i = 1:N
fits(i) = fitness(all_selected(i,:));
end
[values idx] = sort(fits);
selected = population(idx(1:K),:);
end
تابع انتخاب باقی مانده:
function selected = survival_selection(population, children)
% This function returns the new population by replcing the worst ones
fits = zeros(1,length(population));
for i = 1:length(population)
fits(i) = fitness(population(i,:));
end
[values idx] = sort(fits);
population(idx(end-1),:) = children(1,:);
population(idx(end),:) = children(2,:);
selected = population;
end
تابع نمایش:
function show(chrom)
ground = [1 0 1 0 1 0 1 0
0 1 0 1 0 1 0 1
1 0 1 0 1 0 1 0
0 1 0 1 0 1 0 1
1 0 1 0 1 0 1 0
0 1 0 1 0 1 0 1
1 0 1 0 1 0 1 0
0 1 0 1 0 1 0 1];
items = zeros(8,8);
for i = 1:8
items(chrom(i),i) = 5;
end
board = ground+items;
board(board>5) = 5;
imagesc(board)
axis equal
end
تابع اصلی(main) :
close all
clear
clc
% Population Size
pop_size = 100;
% Population Initialization
pop = zeros(pop_size,8);
for i = 1:pop_size
pop(i,:) = randperm(8);
end
found = 0;
fits = zeros(100,1);
for iter = 1:1000
if found == 1
disp('Result is Found ...')
show(result)
result
break
end
% Parent Selection
parents = parent_selection(pop,5,2);
% Crossover
children = crossover(parents);
% Mutation
p = rand();
if p <= 0.8
children = mutation(children);
end
% Survival Selection
pop = survival_selection(pop, children);
% Finding The Best Solution
for i = 1:length(pop)
fits(i) = fitness(pop(i,:));
if fits(i) == 0
result = pop(i,:);
found = 1;
end
end
end
کاربرد های الگوریتم ژنتیک
الگوریتم های ژنتیک کاربردهای گستردهای در زمینههای مختلف مانند مهندسی، علوم کامپیوتر، اقتصاد، زیست شناسی و غیره دارند، در اینجا برخی از مشکلات رایج که با استفاده از الگوریتم ژنتیک حل شدهاند آورده شده است:
- مسائل بهینه سازی: الگوریتمهای ژنتیک را میتوان برای یافتن راهحلهای بهینه یا نزدیک به بهینه برای انواع مسائل بهینه سازی، مانند TSP و مسئله کوله پشتی استفاده کرد.
- یادگیری ماشین: الگوریتمهای ژنتیک را میتوان برای بهینه سازی ابرپارامترهای مدلهای یادگیری ماشینیادگیری ماشین چیست و چرا مهم است؟ - Machine learning (ML)
 تعریف یادگیری ماشین : ماشین لرنینگ (Machine Learning یا به اختصار ML) باعث میشود که خود ماشینها با آنالیز داده ها امکان یادگیری و پیشرفت داشته باشند، مانند نرخ یادگیری، اندازه دستهای و تعداد لایهها، برای بهبود عملکرد آنها استفاده کرد.
تعریف یادگیری ماشین : ماشین لرنینگ (Machine Learning یا به اختصار ML) باعث میشود که خود ماشینها با آنالیز داده ها امکان یادگیری و پیشرفت داشته باشند، مانند نرخ یادگیری، اندازه دستهای و تعداد لایهها، برای بهبود عملکرد آنها استفاده کرد. - پردازش تصویر: الگوریتمهای ژنتیک را میتوان برای بهینه سازی الگوریتمهای پردازش تصویرپردازش تصویر دیجیتال چیست؟ چه انواعی دارد؟ چه مراحلی را شامل میشود؟
 پردازش تصویر یکی از فیلدهای پرطرفدار مرتبط با گرافیک کامپیوتر، بینایی کامپیوتر، هوش مصنوعی، یادگیری ماشین، و الگوریتمها و محاسبات است که ارتباط تنگاتنگی میان تمام آنهاست. در نتیجه در این صفحه علاوه بر معرفی این فیلد، نقشه راهی نیز برای علاقهمندان این حوزه ارائه کردهایم.، مانند تشخیص لبه، تقسیمبندی تصویر و استخراج ویژگیها برای بهبود دقت و کارایی آنها استفاده کرد.
پردازش تصویر یکی از فیلدهای پرطرفدار مرتبط با گرافیک کامپیوتر، بینایی کامپیوتر، هوش مصنوعی، یادگیری ماشین، و الگوریتمها و محاسبات است که ارتباط تنگاتنگی میان تمام آنهاست. در نتیجه در این صفحه علاوه بر معرفی این فیلد، نقشه راهی نیز برای علاقهمندان این حوزه ارائه کردهایم.، مانند تشخیص لبه، تقسیمبندی تصویر و استخراج ویژگیها برای بهبود دقت و کارایی آنها استفاده کرد. - سیستمهای کنترل: الگوریتمهای ژنتیک را میتوان برای بهینهسازی سیستمهای کنترل برای کاربردهای مختلف مانند روباتیک، هوافضا و ساخت استفاده کرد.
- پردازش سیگنال: الگوریتمهای ژنتیک میتوانند برای بهینهسازی الگوریتمهای پردازش سیگنال، مانند فیلتر کردن، فشردهسازی و استخراج ویژگیها برای بهبود عملکردشان استفاده شوند.
- دادهکاوی: الگوریتمهای ژنتیک میتوانند برای بهینهسازی الگوریتمهای داده کاویداده کاوی چیست؟ بررسی 0 تا 100 دیتا ماینینگ (data mining)این مقاله عالی بررسی کرده که داده کاوی یا دیتا ماینینگ (data mining) چیست و چه کاربردی دارد، سپس انواع روش های داده کاوی و مزایای دیتا ماینینگ را بررسی کرده، مانند خوشهبندی، قواعد کاوی و طبقهبندی برای بهبود دقت و کارایی آنها استفاده شوند.



به طور کلی الگوریتم های ژنتیک ابزار قدرتمندی برای حل مسائل پیچیده بهینه سازی هستند که حل آنها با استفاده از روشهای سنتی دشوار است، آنها به ویژه برای مشکلاتی که راهحلهای ممکن زیادی وجود دارد و فضای جستجو بسیار بزرگ است مفید هستند.
در ادامه ۲ مسئله از این سری مسائل را بررسی میکنیم:
مسئله فروشنده دوره گرد
مسئله فروشنده دوره گرد (TSP) یک مسئله کلاسیک در علوم کامپیوترعلوم کامپیوتر یا کامپیوتر ساینس چیست در این صفحه به بررسی و موشکافی رشته علوم کامپیوتر اعم از بررسی بازار کار، گرایشها، دروس و چارت درسی این رشته، میزان درآمد و حقوق فارغ التحصیلان این رشته و ادامه تحصیل در این رشته پرداخته شده است. و تحقیقات عملیاتی است، این مسئله به صورت زیر تعریف میشود:
در این صفحه به بررسی و موشکافی رشته علوم کامپیوتر اعم از بررسی بازار کار، گرایشها، دروس و چارت درسی این رشته، میزان درآمد و حقوق فارغ التحصیلان این رشته و ادامه تحصیل در این رشته پرداخته شده است. و تحقیقات عملیاتی است، این مسئله به صورت زیر تعریف میشود:
با توجه به لیستی از شهرها و فواصل بین هر جفت شهر، کوتاه ترین مسیر ممکن که دقیقاً یک بار از هر شهر بازدید می کند و به شهر شروع باز می گردد کدام است؟
TSP به عنوان یک مسئله NP-hard شناخته می شود، به این معنی که زمان مورد نیاز برای یافتن راهحل بهینه به طور تصاعدی با تعداد شهرها افزایش مییابد. به عنوان مثال، اگر ۱۰ شهر وجود داشته باشد، ۳،۶۲۸،۸۰۰ مسیر ممکن وجود دارد، اما اگر ۱۰۰ شهر وجود داشته باشد، تقریباً مسیر ممکن وجود دارد!

برای حل TSP از الگوریتم ژنتیک استفاده شده است، در مورد TSP، یک الگوریتم ژنتیک با جمعیتی از راهحلهای بالقوه (یعنی مسیرهای عبوری از شهرها) شروع میشود و از عملگرهای ژنتیکی مانند متقاطع، جهش و انتخاب برای تولید جمعیتهای جدید راهحلهای بالقوه استفاده میکند. با گذشت زمان، الگوریتم ژنتیک روی یک راه حل تقریباً بهینه همگرا میشود.
در اینجا مثالی میبینیم که چگونه یک الگوریتم ژنتیک می تواند TSP را حل کند:
- مقداردهی اولیه: الگوریتم ژنتیک با جمعیتی از راه حل های بالقوه شروع می شود، جایی که هر راهحل به عنوان دنبالهای از شهرها نشان داده میشود. جمعیت به صورت تصادفی یا با استفاده از برخی روشهای اکتشافی تولید میشود.
- ارزیابی: هر راهحل بالقوه بر اساس تناسب آن ارزیابی میشود که به عنوان طول مسیر در شهرها تعریف میشود، هرچه مسیر کوتاهتر باشد، تناسب بالاتری دارد. این کار با محاسبه کل مسافت طی شده توسط مسیر انجام میشود.
- انتخاب: الگوریتم ژنتیک بهترین راهحلها را از بین جمعیت انتخاب میکند تا والدین نسل بعدی باشند، این فرآیند انتخاب معمولاً بر اساس ارزش تناسب هر راهحل است. رایجترین روشهای انتخاب عبارتند از انتخاب مسابقات و انتخاب چرخ رولت.
- تولید مثل: الگوریتم ژنتیک از عملگرهای ژنتیکی مانند ترکیب و جهش برای ایجاد راهحلهای بالقوه جدید از والدین انتخاب شده استفاده میکند. در ترکیب، والدین با یکدیگر ترکیب میشوند تا با مبادله بخشهایی از مواد ژنتیکی خود، فرزندان جدیدی ایجاد کنند. در جهش، یک تغییر تصادفی کوچک در یک والد برای ایجاد یک فرزند جدید ایجاد میشود.
- ارزیابی: تناسب راهحلهای بالقوه جدید ارزیابی میشود. این مرحله همانند مرحله 2 است.
- خاتمه: الگوریتم ژنتیک زمانی خاتمه می یابد که یک راهحل رضایت بخش پیدا شود (یعنی کوتاه ترین مسیر ممکن از طریق شهرها) یا زمانی که به حداکثر تعداد نسل رسیده باشد. بهترین راه حل یافت شده در طول اجرای الگوریتم به عنوان نتیجه برگردانده میشود.
الگوریتم ژنتیک مراحل ۳-۵ را تکرار می کند تا یک راهحل رضایت بخش پیدا شود،الگوریتم ژنتیک قادر است با استفاده از مراحل انتخاب، تولید مثل و ارزیابی به یک راه حل نزدیک به بهینه همگرا شود تا جمعیتهای جدیدی از راهحلهای بالقوه تولید کند که به طور فزایندهای بهتر هستند. با ترکیب عملگرهای ژنتیکی مختلف، الگوریتم ژنتیک قادر است فضای حل را کاوش کند و یک راه حل بهینه یا نزدیک به بهینه برای TSP پیدا کند.
مسئله کوله پشتی
مسئله کوله پشتی یک مسئله بهینه سازی است که در آن باید یک کوله پشتی را با مجموعه ای از آیتمها پر کنیم که هر کدام وزن و مقداری دارند، به طوری که وزن کل کوله پشتی از ظرفیت معینی تجاوز نکند و مقدار کل موارد موجود در کوله پشتی به حداکثر برسد. این مسئله NP-hard است، به این معنی که یافتن راهحل دقیق برای نمونههای بزرگ مسئله میتواند از نظر محاسباتی غیرقابل حل باشد. یکی از روشهای حل مسئله کوله پشتی استفاده از الگوریتم ژنتیک است. الگوریتم ژنتیک با ایجاد جمعیتی از راهحلهای بالقوه کار میکند که هر کدام ترکیب احتمالی از آیتمهایی را که باید در کولهپشتی گنجانده شوند، نشان میدهند. هر راهحل به صورت رشته ای از ارقام باینری نمایش داده میشود که هر بیت نشان میدهد که آیا آیتم مربوطه در کوله پشتی گنجانده شده است یا خیر.

سپس الگوریتم ژنتیک از طریق یک سری نسل پیش میرود که در آن هر نسل شامل مراحل زیر است:
- انتخاب: زیرمجموعهای از افراد بر اساس تابع برازندگی از بین افراد انتخاب میشود که با ارزش کل اقلام موجود در کوله پشتی برای آن فرد تعیین میشود.
- متقاطع: دو فرد از زیر مجموعه انتخاب میشوند و رشتههای بیت آنها برای ایجاد یک فرد جدید با استفاده از یک عملگر ترکیب، ترکیب میشوند. عملگر ترکیب به طور تصادفی یک نقطه از رشتههای بیت را انتخاب میکند و بیتهای بعد از آن نقطه را بین والدین تعویض میکند.
- جهش: رشته بیت فرد جدید تحت یک عملگر جهش قرار میگیرد که به طور تصادفی برخی از بیتها را برمیگرداند.
- جایگزینی: سپس فرد جدید به جمعیت اضافه میشود و جایگزین یکی از افراد کم تناسب میشود.
سپس الگوریتم ژنتیک این فرآیند را برای تعداد ثابتی از نسلها یا تا زمانی که راهحل رضایت بخشی پیدا شود تکرار میکند.
با استفاده از الگوریتمهای ژنتیک برای حل مسئله کولهپشتی، میتوان راهحلهای تقریباً بهینهای را برای نمونههای بزرگی از مسئله پیدا کرد، جایی که روشهای دیگری مانند brute-force یا برنامهنویسی پویا ممکن است غیرعملی باشند.
نمونه سوال الگوریتم ژنتیک
- الگوریتم ژنتیک چیست و چگونه کار میکند؟
پاسخ: الگوریتم ژنتیک یک الگوریتم بهینه سازی فراابتکاری است که از فرآیند انتخاب طبیعی الهام گرفته شده است. با ایجاد جمعیتی از راه حل های بالقوه کار می کند که هر کدام با مجموعه ای از پارامترها یا متغیرهای تصمیم نشان داده می شوند. سپس افراد بر اساس یک تابع برازندگی ارزیابی می شوند. سپس الگوریتم از طریق یک سری از نسلها ادامه مییابد، که در آن هر نسل شامل عملگرهای انتخاب، ترکیب، جهش و جایگزینی است، با هدف تکامل جمعیتی از افراد که میتوانند مسئله مورد نظر را حل کنند.
- مزایا و معایب استفاده از الگوریتم ژنتیک چیست؟
پاسخ: از مزایای استفاده از الگوریتم ژنتیک می توان به توانایی آن در یافتن راه حل های خوب برای مسائل پیچیده با پارامترها یا متغیرهای تصمیم گیری زیاد، توانایی آن در رسیدگی به اهداف متعدد و توانایی آن در جستجوی کل فضای راه حل اشاره کرد. معایب استفاده از الگوریتم ژنتیک شامل حساسیت آن به تنظیمات پارامتر، تمایل آن به گیر افتادن در بهینه محلی و ناتوانی آن در تضمین بهینه بودن یا همگرایی است.
- تابع برازندگی در الگوریتم ژنتیک چیست و چگونه از آن استفاده میشود؟
پاسخ: تابع برازندگی در الگوریتم ژنتیک تابعی است که کیفیت تک تک افراد جامعه را ارزیابی میکند. این تابع اندازه گیری میکند که چگونه یک فرد مسئله را حل میکند و برای هدایت تکامل جمعیت استفاده میشود. افراد با برازندگی بالاتر به احتمال زیاد برای ترکیب و جهش انتخاب میشوند، در حالی که افرادی که برازندگی پایین تری دارند، احتمال بیشتری برای جایگزینی دارند. تابع برازندگی را میتوان بسته به مشکل حل شده به روشهای مختلفی تعریف کرد، اما باید به گونهای طراحی شود که هدف یا اهداف مسئله را منعکس کند.
- ترکیب در الگوریتم ژنتیک چیست و چگونه کار میکند؟
پاسخ: ترکیب در الگوریتم ژنتیک یک عملگر ژنتیکی است که دو فرد والد را برای ایجاد یک فرد جدید ترکیب میکند. با انتخاب یک نقطه تصادفی در رشته بیت یا فضای پارامتر والدین و مبادله بخشهای بعد از آن نقطه برای ایجاد دو فرزند کار میکند. هدف ترکیب تبادل ویژگی های خوب افراد والدین و ایجاد افراد جدید و بالقوه بهتر است. نرخ ترکیب را میتوان برای کنترل تعادل بین اکتشاف و بهرهبرداری در فرآیند جستجو تنظیم کرد.
- جهش در الگوریتم ژنتیک چیست و چگونه کار میکند؟
پاسخ: جهش در الگوریتم ژنتیک یک عملگر ژنتیکی است که تغییرات تصادفی را به یک فرد در جمعیت معرفی میکند. با انتخاب یک بیت یا مقدار پارامتر تصادفی در فرد و تغییر آن به یک مقدار جدید کار میکند. هدف جهش معرفی افراد جدید و بالقوه بهتر به جمعیت و جلوگیری از گیرکردن الگوریتم در بهینه محلی است. نرخ جهش را میتوان برای کنترل تعادل بین اکتشاف و بهرهبرداری در فرآیند جستجو تنظیم کرد.
- یک الگوریتم ژنتیک با اندازه جمعیت 50 نفر و 10 متغیر تصمیم را در نظر بگیرید. متغیرهای تصمیم با اعداد واقعی در محدوده [0، 1] نشان داده میشوند. تابع برازندگی به عنوان مجموع متغیرهای تصمیم تعریف میشود، مشروط به این محدودیت که مجموع مربعات متغیرهای تصمیم باید کمتر یا مساوی 1 باشد. الگوریتم از انتخاب مسابقات با اندازه مسابقات 3، ترکیب یکنواخت استفاده میکند. با احتمال 0.6 و جهش گاوسی با احتمال 0.05 و انحراف معیار 0.1. پس از 100 نسل، بهترین فرد یافت شده دارای برازندگی 8.67 است.
الف) تعداد کل ارزیابی های تابع تناسب انجام شده توسط الگوریتم را محاسبه کنید.
ب) میانگین برازندگی جمعیت در نسل نهایی را محاسبه کنید.
ج) احتمال انتخاب فردی با برازندگی 8.0 در نسل نهایی را محاسبه کنید، با این فرض که همه افراد با برازندگی بین 8.0 و 9.0 احتمال انتخابی برابری دارند.
پاسخ:
الف) تعداد کل ارزیابیهای تابع برازندگی برابر است با اندازه جمعیت ضرب در تعداد نسل ها که 50*100 = 5000 ارزیابی است.
ب) میانگین برازندگی جمعیت در نسل نهایی برابر است با مجموع مقادیر برازندگی همه افراد جامعه تقسیم بر اندازه جمعیت. از آنجایی که بهترین فرد یافت شده دارای برازندگی 8.67 است، می توانیم فرض کنیم که میانگین برازندگی جمعیت کمی کمتر از آن است، مثلاً 8.5.
ج) احتمال انتخاب فردی با برازندگی 8.0 در نسل نهایی برابر است با نسبت افراد در جمعیت با برازندگی 8.0 ضرب در احتمال انتخاب یکی از آن افراد. ما نسبت دقیق افراد با برازندگی 8.0 را نمیدانیم، اما میتوانیم فرض کنیم که نسبت به برازندگی بین 8.0 و 9.0 نسبتاً کوچک است. فرض کنید 5 نفر با برازندگی 8.0 در نسل نهایی و 200 نفر با برازندگی بین 8.0 و 9.0 وجود دارند. سپس احتمال انتخاب فردی با برازندگی 8.0 تقریباً 5/(5+200) = 0.024 است.
آرایه در ساختمان داده چیست و چگونه در حافظه ذخیره میشود؟
به مجموعهای از دادههای پشت سر هم حافظه که همگی از یک نوع بوده و از آدرس مشخصی شروع میشوند، آرایه گفته میشود. آرایه سادهترین ساختمان دادهای است که در آن میتوان به هر داده مستقیماً تنها با استفاده از شماره اندیس آن دسترسی داشت.
مثلا اگر بخواهیم نمرههای کسب شده توسط یک دانش آموز را در 5 موضوع ذخیره کنیم، دیگر نیازی به تعریف متغیرهای جداگانه برای هر موضوع نیست بلکه میتوانیم آرایهای تعریف کنیم که عناصر داده را در مکانهای پشت سر هم حافظه ذخیره کند. به منظور آشنایی بیشتر میتوانید به ابتدای مقاله مراجعه کنید.
چرا آرایه در برنامه نویسی اهمیت دارد؟
در برنامه نویسی اغلب نیاز به ذخیره حجم زیادی از دادهها از نوع مشابه داریم؛ برای ذخیره چنین حجم عظیمی از دادهها باید متغیرهای متعددی تعریف کرد. همچنین لازم است در حین نوشتن برنامه، نام همه متغیرها به خاطر سپرده شود که بسیار سخت است. برای حل این موضوع در برنامه نویسی بهتر است یک آرایه تعریف کرده و همه عناصر را در آن ذخیره کنیم.






































