
برای شروع حرفهای کنکور ارشد کامپیوتر،آیتی و علوم کامپیوتر حتما روی عکس زیر کلیک کنید تا در کانال کنکور کامپیوتر عضو شوید، در این کانال به معرفی بهترین منابع کنکور ارشد،برنامه ریزی و مشاوره، معرفی گرایشها و هر آنچه برای موفقیت در کنکور ارشد نیاز دارید پرداخته شده است

در این صفحه نمونه سوالات ساختمان داده با پاسخ تشریحی برای شما عزیزان قرار داده شده است، سعی شده مثال های ساختمان داده تمامی مباحث ساختمان داده را در بر گیرد. در صورتی که علاقه دارید تا بیشتر با درس ساختمان داده آشنا شوید و فیلم های رایگان ساختمان داده را مشاهده کنید به صفحه معرفی و بررسی آموزش ساختمان دادهآموزش ساختمان داده و الگوریتم هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است مراجعه کنید.
هر ساختمان داده یک نوع فرمت ذخیرهسازی و مدیریت دادهها در کامپیوتر است، که امکان دسترسی و اصلاح کارآمد آن دادهها را برای یکسری از الگوریتمها و کاربردها فراهم میکند، در این صفحه به بررسی و آموزش ساختمان داده و الگوریتم پرداخته شده است مراجعه کنید.
قبل از اینکه به ادامه مقاله نمونه سوالات ساختمان داده بپردازیم توصیه میکنیم که فیلم زیر که در خصوص تحلیل و بررسی درس ساختمان داده رشته کامپیوتر است را مشاهده کنید، در این فیلم توضیح داده شده که فیلم درس ساختمان داده برای چه افرادی مناسب است و همین طور در خصوص فصول مختلف درس ساختمان داده و اهمیت هر کدام از فصول ساختمان داده صحبت شده است.
در ادامه این مقاله فیلم های رایگان ساختمان داده که به آنها نیاز دارید نیز در اختیارتان قرار گرفته است.
در زیر فیلم های ساختمان داده قرار داده شده است و در این فیلم ها نمونه سوالات زیادی از ساختمان داده حل شده است.
همچنین پس از این بخش، نمونه سوالات ساختمان داده زیادی در اختیار شما عزیزان قرار گرفته است.
فیلم های رایگان ساختمان داده که به آنها نیاز دارید

فیلم ساختمان داده جلسه 1

فیلم ساختمان داده جلسه 2

فیلم ساختمان داده جلسه 3

فیلم ساختمان داده جلسه 4

فیلم ساختمان داده جلسه 5

فیلم ساختمان داده جلسه 6

فیلم ساختمان داده جلسه 7

فیلم ساختمان داده جلسه 8

حل تست ساختمان و الگوریتم جلسه 1

حل تست ساختمان و الگوریتم جلسه 2

حل تست ساختمان و الگوریتم جلسه 3

ساختمان داده و طراحی الگوریتم کامپیوتر 1403

ساختمان داده و طراحی الگوریتم آیتی 1403

حل تست ساختمان و الگوریتم جلسه 4

انواع پیمایشهای درخت

نحوه ساخت درخت BST

آموزش درخت B-Tree

بررسی مرتبه ساخت هیپ

آموزش مرتب سازی سریع

آموزش شبکه شار

حل سوالات ساختمان ارشد کامپیوتر 99

حل ساختمان ارشد 95 بخش 1

حل ساختمان ارشد 95 بخش 2
خرید فیلم های ساختمان داده
در حال حاضر فیلم آموزش ساختمان داده استاد رضوی پرطرفدارترین و پرفروشترین فیلم آموزشی ساختمان داده و الگوریتم کشور است و هر سال بیش از ۶۰۰۰ نفر این فیلم را تهیه میکنند

ویدیو درس ساختمان داده
تخفیف تا ۱۸ خرداد
ویدیو نکته و تست ساختمان داده و طراحی الگوریتم
تخفیف تا ۱۸ خرداد
خب حالا مجددا به توضیح نمونه سوالات در ساختمان داده ادامه میدهیم
نمونه سوالات مرتبه زمانی درس ساختمان داده
در زیر نمونه سوالات بسیار متنوعی از ساختمان داده را برای شما آورده ایم و سعی کردیم که از همه مباحث ساختمان داده نمونه سوالاتی با پاسخ تشریحی برای شما قرار دهیم، جامعیت و تنوع نمونه سوالات ساختمان داده ای که برای شما قرار دادیم حتما نیاز شما را بر طرف خواهد کرد.
$Func\left(n\right)$
$\ \ \ \ \ \ tmp=\circ;$
$\ \ \ \ \ \ for\left(i=\frac{n}{2};i\le n;i++\right)$ $\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ for\left(\mathcal{j}=2;\mathcal{j}\le n;\mathcal{j}=2\mathcal{j}\right)$ $\ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ \ tmp=tmp+\frac{n}{2};$
$return~tmp;$
$~i=n;$
$~\mathcal{w}hile\ \ \ i>1\ \ do$ $~\{$ $~~~~~~~~{j}=1$ $~~~~~~~~while~j \lt n~do$ $~~~~~~~~~~~\{$ $~~~~~~~~~~~~~~~~{j}=\mathcal{j}\ast3;$ $~~~~~~~~~~~~~~~~~i =\frac{i}{2};$ $~~~~~~~~~~~~~~~~~{x}+=1;$ $~~~~~~~~~~~\}$ $~\}$
با هر بار تکرار حلقه بیرونی (حلقهای که شرط خاتمهاش روی i است)، حلقه داخلی $log_۳^n$ بار اجرا میشود و در هربار اجرا حلقه داخلی؛ i تقسیم بر ۲ میشود و این بدان معناست که i در هر بار اجرا حلقه بیرونی تقسیم بر $۲^{log_{۳}^n}$ میشود و این کار تا زمانی ادامه دارد که $i>۱$ باشد. بنابراین حلقه خارجی $log_{{۲}^{log_۳^n }}^n$ بار اجرا میشود که در هر بار اجرا آن حلقه داخلی $log_۳^n$ بار اجرا میشود، بنابراین تعداد اجزا جمله $x+=۱$ برابر است با:
(نکته: $log_{c^d}^{a^b }=\frac{b}{a} log_c^a$) $log_{۲^{log_۳^n }}^n\times log_۳^n= \frac{۱}{log_۳^n}\times log_۲^n\times log_۳^n=log_۲^n$
$\left\{ \matrix{ {G_n} = {{{G_{n - 1}} + {H_{n - 1}}} \over 2},{H_n} = {A \over {{G_n}}},|{G_{n - 1}} - {H_{n - 1}}| \ge ERR \hfill \cr {G_1} = 1,{H_1} = {A \over {{G_1}}} \hfill \cr} \right.$
(ERR، مقدار کرانه خطای محاسبات و یا به عبارتی دقت جواب را بیان میکند.) به دست آوردن مرتبه زمانی شبه کدها
از روی گزینهها میفهمیم که قرار است روی A یک عملیات انجام شود، پس مثلا به ازای 9=A سوال را بررسی میکنیم.
$G_{\mathrm{1}}=\mathrm{1}\mathrm{,\ }H_{\mathrm{1}}=\frac{\mathrm{9}}{\mathrm{1}}=\mathrm{9}$
$G_{\mathrm{2}}=\frac{G_{\mathrm{1}}+H_{\mathrm{1}}}{\mathrm{2}}=\frac{\mathrm{1}\mathrm{+}\mathrm{9}}{\mathrm{2}}\mathrm{=}\mathrm{5\ }\mathrm{,\ }H_{\mathrm{2}}\mathrm{=}\frac{\mathrm{9}}{\mathrm{5}}\mathrm{=}\mathrm{1/8}$
$G_{\mathrm{3}}=\frac{\mathrm{5}+\mathrm{1/8}}{\mathrm{2}}=\frac{\mathrm{34}}{\mathrm{10}}\mathrm{=}\mathrm{3/4\ }\mathrm{,\ }H_{\mathrm{3}}\mathrm{=}\frac{\mathrm{9}}{\mathrm{3/4}}\mathrm{\simeq }\mathrm{2/64}$
$G_{\mathrm{4}}=\frac{\mathrm{3/4}+\mathrm{2/64}}{\mathrm{2}}=\mathrm{3/02\ }\mathrm{\ ,\ }H_{\mathrm{4}}\mathrm{=}\frac{\mathrm{9}}{\mathrm{3/02}}\mathrm{\simeq }\mathrm{2/9}$
مشخص است که $A = {H_n} \times {G_n}$ است و هدف کم کردن اختلاف ${G_n},{H_n}$. پس در واقع $A = {G_n} \times {G_n}$؛ داریم:
$G^{\mathrm{2}}_n=A\Rightarrow G_{\mathrm{n}}=\sqrt{A}$
${\rm{function(int~n) \{ }\qquad \qquad\qquad\qquad}$ ${\rm{if(n = = 1)return;}\qquad\qquad\qquad}$ ${\rm{for(int~i = 1;i \le n;i + + )\{ }~~~~~}$ ${\rm{for(int~j = 1;j \le n;j + + )\{ }}$ ${\rm{printf("*");}\qquad\qquad~~~~~}$ ${\rm{break;\} \} }\qquad\qquad\qquad~~}$ ${\rm{\} ~~}\qquad \qquad\qquad\qquad\qquad\qquad}$
${\rm{function(int~n) \{ }\qquad \qquad\qquad\qquad}$ ${\rm{if(n = = 1)return;}\qquad\qquad\qquad}$ ${\rm{for(int~i = 1;i \le n;i + + )\{ }~~~~~}$ ${\rm{for(int~j = 1;j \le n;j + + )\{ }}$ ${\rm{printf("*");}\qquad\qquad~~~~~}$ ${\rm{function(n-3);\} \} }\qquad\qquad}$ ${\rm{\} ~~}\qquad \qquad\qquad\qquad\qquad\qquad}$
Function(int n){
$\qquad$ If(n==l) return;$\mathrel{\mathop{\kern0pt\longrightarrow}
\limits_{}} $O(l)
$\qquad$ for(int i=l;i $\le$ n;i++){$\mathrel{\mathop{\kern0pt\longrightarrow}
\limits_{}} $O(n)
$\qquad\qquad$for(int j=l;j $\le$ n;j++){$\mathrel{\mathop{\kern0pt\longrightarrow}
\limits_{}} $O(l)
$\qquad\qquad\qquad$Printf(''*'');
$\qquad\qquad\qquad$Break;}}
}
برای الگوریتم B رابطه بازگشتی $T(n)=T(n-\mathrm{3}\mathrm{)}+n^{\mathrm{2}}$ را داریم که با استفاده از تئوری مستر میزان پیچیدگی برابر با $O(n^{\mathrm{3}})$ میباشد.
یادآوری: تئوری مستر
$T(n) = \left\{ \matrix{\qquad\qquad
c\qquad~~~~,ifn \le {\rm{1}} \hfill \cr aT(n - b) + f(n),ifn > {\rm{1}} \hfill \cr} \right.$
به شرطی که $b\ge 0\mathrm{,\ k\ }\mathrm{\ge }0$ و $c,a > 0$، اگر مرتبه تابع برابر با $\mathrm{f(n)=O(}n^k\mathrm{)}$، باشد، آن گاه داریم:
$T(n) = \left\{ \matrix{
{\rm{O}}\left( {{n^k}} \right)~~~~~~\qquad,\qquad ifa \lt {\rm{1}} \hfill \cr {\rm{O}}\left( {{n^{k + {\rm{1}}}}} \right)~~\qquad,\qquad ifa = {\rm{1}} \hfill \cr {\rm{O}}\left( {{n^k}{a^{{n \over b}}}} \right)\qquad,\qquad ifa > {\rm{1}} \hfill \cr} \right.$
نمونه سوالات رشد توابع درس ساختمان داده
به سادگی باید توابع را با یکدیگر مقایسه کنیم:
یاددآوری) دقت کنید $log^2 n$ با $log n^2$ برابر نیست بلکه $log^2\ n=log\ n\ast log\ n$ و $log\ n^2=2log\ n$
نکته) 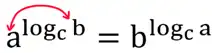
اثبات نکته بالا:
یاددآوری: با توجه به فرمول روبه رو میتوان مبنا را تغییر داد: $log_c b = \frac{log _d b}{log_d c}$
$a^{{{log}_c b\ }}=b^{{{log}_c a\ }}{{\stackrel{\text{از دو طرف میگیریم} \ log}{\Longrightarrow}}}{log(a}^{{{log}_c b\ }})=log(b^{{{log}_c a\ }})\to {{log}_c (b)\ }\ *\ log(a)={{log}_c (a)\ *\ log(b)\to \frac{{{log}_{10} b\ }}{{{log}_{10} c\ }}\ }*log(a)=\frac{{{log}_{10} a\ }}{{{log}_{10} c\ }}*log(b)$
حال با توجه به نکات بالا میفهمیم که $f(n)=4^{log\ n}=n^2$ حال به مقایسهی این توابع میپردازیم.
${f(n)=4}^{log\ n}\ ?h(n)={{log}^2 n\ }\to \ n^2>{{log}^2 n\ }$
چون هر توان ثابتی از $n$ از هر توان ثابتی از $log\ n$ رشد بیشتری دارد.
برای تشخیص ${f(n)=4}^{log\ n}\ ?\ g(n)={(log\ n)}^{log\ n}$ دو راه داریم (البته مشخص است که دو تابع با توان یکسان داریم و پایههای یکی عدد ثابت و دیگری $log\ n$ است پس $g(n)$ بزرگتر است):
1- با استفاده از حد نشان دهیم رشد کدام بیشتر است.
${\mathop{lim}_{n\to \infty } \frac{f\left(n\right)}{h(n)}=\mathop{lim}_{n\to \infty }\frac{4^{log\ n}}{{(log\ n)}^{log\ n}}\ }=\mathop{lim}_{n\to \infty }{(\frac{4}{log\ n})}^{{log n\ }}=0$
از آنجا که نسبت یک عدد ثبات به $log\ n$ صفر خواهد شد میفهمیم که $4^{log\ n} \lt (log\ n)^{log\ n}$ پس داریم:
$f(n) \in O(h(n))$ یا $h(n)\in \Omega (f(n))$
2- با توجه به اینکه هردو تابع صعودی و بزرگتر از یک هستند از روی رشد $log$هایشان نیز میتوان مشخص نمود:
${f(n)=4}^{log\ n}\ ?\ g(n)={(log\ n)}^{log\ n}\stackrel{\text{از دو طرف میگیریم}\ log}{\Longrightarrow}log(4^{log\ n}){\ ?\ log((log\ n))}^{log\ n}\to log(n)*log(4) \lt log(n)*log(log(n))\to f(n)\lt g(n)$
پس داریم:
$f(n) \in O(g(n))$ یا $g(n) \in \Omega (f(n))$
برای تشخیص $h(n)= log ^2 \ n \ ? \ g(n)= (log \ n)^{log \ n}$ دو راه داریم (البته مشخص است که دو تابع با پایه یکسان داریم و توان یکی عدد ثابت و دیگری $log\ n$ است پس $g(n)$ بزرگتر است):
1- با استفاده از حد نشان دهیم رشد کدام بیشتر است.
${\mathop{lim}_{n\to \infty } \frac{g\left(n\right)}{h(n)}=\mathop{lim}_{n\to \infty }\frac{{(log\ n)}^{log\ n}}{{{\ log}^2 n\ }}\ }=\mathop{lim}_{n\to \infty }{(log\ n)}^{{log n\ }-2}=\infty $
از آنجا که نسبت یک برابر با بینهایت شد میفهمیم که $log^2\ n\ \lt \ (log\ n)^{log\ n}$
2- با توجه به اینکه هردو تابع صعودی و بزرگتر از یک هستند از روی رشد $log$هایشان نیز میتوان مشخص نمود:
$h\left(n\right)={{\ log}^2 n\ }?g\left(n\right)={\left(logn\right)}^{log\ n}\stackrel{\text{از دو طرف میگیریم}\ log}{\Longrightarrow}log\left({{log}^2 n\ }\right){?log\left(\left(logn\right)\right)}^{log\ n}\to 2log\left(n\right) \lt log\left(n\right)*log\left(log\left(n\right)\right)\to h\left(n\right) \lt g\left(n\right)$
پس داریم:
$h(n) \in O(g(n))$ یا $g(n)\in \Omega (h(n))$ و در کل میفهمیم که $h(n)\lt f(n)\lt g(n)$
حال با توجه به توضیحات بالا میفهمیم که گزینه صحیح است.
یاددآوری:
Big O: تابع f(n) از مرتبه O(g(n)) است هرگاه رشد f کمتر مساوی رشد g باشد.
$\mathrm{f}\left(\mathrm{n}\right)\mathrm{\in }\mathrm{O}\left(\mathrm{g}\left(\mathrm{n}\right)\right)\mathrm{\to }\mathrm{\exists }\mathrm{c,}{\mathrm{n}}_0\mathrm{>0\ ,\ }\mathrm{\forall }\mathrm{\ n}\mathrm{\ge }\mathrm{\ }{\mathrm{n}}_0\mathrm{\ }\mathrm{\Rightarrow }\mathrm{\ }\underbrace{0}_{\text{رشد}\mathrm{\ }\text{برای}\mathrm{\ }\text{توابع}\mathrm{\ }\text{منفی}\mathrm{\ }\text{معنی}\mathrm{\ }\text{ندارد}}\mathrm{\le }\mathrm{f}\left(\mathrm{n}\right)\mathrm{\le }\mathrm{c.g(n)}$
O بزرگ کران بالا را مشخص میکند.
دقت شود O یک مجموعه است و در نتیجه توابع میتوانند عضو این مجموعه باشند اما به صورت اشتباه رایج از مساوی برای عضویت استفاده میشود.
$\mathrm{O}\left({\mathrm{n}}^{\mathrm{2}}\right)\mathrm{=}\mathrm{\{}\mathrm{\dots ,\ log}\left(\mathrm{n}\right)\mathrm{,\ }\frac{\mathrm{1}}{\mathrm{n}}\mathrm{,\ n\ ,\ n.lo}\mathrm{g}\left(\mathrm{n}\right)\mathrm{,\ 3}{\mathrm{n}}^{\mathrm{2}}\mathrm{+5,\ \dots .}\mathrm{\}}$
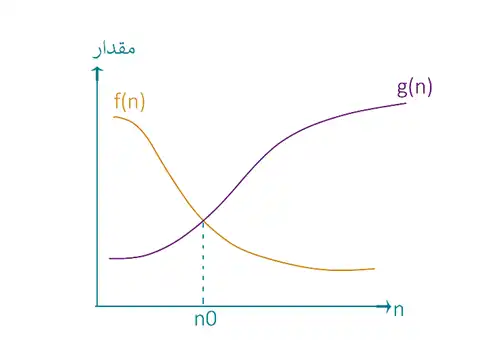
big $\Omega$ : تابع f(n) از مرتبه $\Omega$(g(n)) است هرگاه رشد f بیشتر مساوی رشد g باشد.
$\mathrm{f}\left(\mathrm{n}\right)\mathrm{\in }\mathrm{\Omega }\left(\mathrm{g}\left(\mathrm{n}\right)\right)\mathrm{\to }\mathrm{\exists }\mathrm{c,}{\mathrm{n}}_0\mathrm{>0\ ,\ }\mathrm{\forall }\mathrm{\ n}\mathrm{\ge }\mathrm{\ }{\mathrm{n}}_0\mathrm{\ }\mathrm{\Rightarrow }\mathrm{\ }0\mathrm{\le }\mathrm{c.g}\left(\mathrm{n}\right)\mathrm{\le }\mathrm{f(n)}$
$\Omega$ بزرگ کران پایین را مشخص میکند.
دقت شود $\Omega$ یک مجموعه است و در نتیجه توابع میتوانند عضو این مجموعه باشند اما به صورت اشتباه رایج از مساوی برای عضویت استفاده میشود.
$\mathrm{O}\left({\mathrm{n}}^{\mathrm{2}}\right)\mathrm{=}\mathrm{\{}\mathrm{\dots ,}{\mathrm{n}}^{\mathrm{2}}\mathrm{,\ }{\mathrm{n}}^{\mathrm{3}}\mathrm{,\ n!,\ }{\mathrm{n}}^{\mathrm{2}}\mathrm{log}\left(\mathrm{n}\right)\mathrm{,\dots .}\mathrm{\}}$
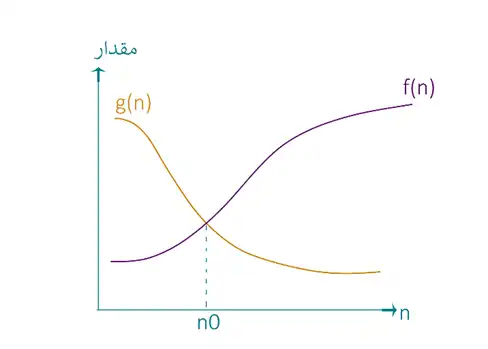
با توجه به خواص مجانبی میتوان عبارات زیر را نتیجه گرفت.
${\mathop{\mathrm{lim}}_{\mathrm{n}\mathrm{\to }\mathrm{\infty }} \frac{\mathrm{f(n)}}{\mathrm{g(n)}}\ }\mathrm{=}\left\{ \begin{array}{c}\mathrm{\infty }\mathrm{\leftrightarrow }\mathrm{f}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\in }\mathrm{\omega }\left(\mathrm{g}\left(\mathrm{n}\right)\right)\mathrm{\leftrightarrow }\mathrm{g}\left(\mathrm{n}\right)\mathrm{\in }\mathrm{o}\left(\mathrm{f}\left(\mathrm{n}\right)\right) \\ \mathrm{0}\mathrm{\leftrightarrow }\mathrm{f}\left(\mathrm{n}\right)\mathrm{\in }\mathrm{o}\left(\mathrm{g}\left(\mathrm{n}\right)\right)\mathrm{\leftrightarrow }\mathrm{g}\left(\mathrm{n}\right)\mathrm{\in }\mathrm{\omega }\left(\mathrm{f}\left(\mathrm{n}\right)\right) \\ \mathrm{0 \lt c \lt }\mathrm{\infty }\mathrm{\leftrightarrow }\mathrm{f}\left(\mathrm{n}\right)\mathrm{\in }\mathrm{\theta }\left(\mathrm{g}\left(\mathrm{n}\right)\right)\mathrm{\leftrightarrow }\mathrm{g}\left(\mathrm{n}\right)\mathrm{\in }\mathrm{\theta }\left(\mathrm{f}\left(\mathrm{n}\right)\right) \end{array}\right.$
$f_۱=lg[(lgn)^۳],~f_۲=(lgn)^{۳lg۳n},~f_۳=۳^{lgn},~f_۴= n^{۳^{lgn}},~f_۵=lg(۳n^{n^{۳}}),~f_۶=(lglgn)^۳$
(خواص لگاریتم) $f_۱=lg[(lgn)^۳ ]=۳lglgn∈O(f_۶=(lglgn)^۳ )$
(توابع چندجملهای از تمامی توابع لگاریتمی با هر توانی رشد سریعتری دارند) $f_۶=(lglgn)^۳∈O(f_۳=۳^{lgn}=n^{lg۳} )$ $f_۳=۳^{lgn}=n^{lg۳}∈O(f_۵=lg(۳n^{n^۳})=n^۳ lg(۳n) )$ (خواص لگاریتم) $f_۵=lg(۳n^{n^۳})=n^۳ lg(۳n)∈O(f_۲=(lgn)^{۳lg۳n}=(lgn)^{lg۲۷n^۳}=(۲۷n^۳ )^{lglgn} )$ $f_۲=(lgn)^{۳lg۳n}=(۲۷n^۳ )^{lglgn}∈O(f_۴=n^{۳^{lgn}}=n^{n^{lg۳}})$
$f(n) = O({n^{\rm{2}}}) \Rightarrow f(n) \le c{n^{\rm{2}}};~\forall n \ge n$
$\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\qquad\Rightarrow c'n~lg~n \le c{n^{\rm{2}}}$
$g(n) \in O(n~lg~n) \Rightarrow g(n) \le c'n~lg~n;~\forall n \ge {n_{\rm{1}}}$
چه وقتی ممکن است نقض شود؟
اگر ${c^{\rm{'}}}$ خیلی بزرگ باشد و c خیلی کوچک باشد.
${{f(n)} \over {g(n)}} \ge 1\buildrel {n,{n_0}} \over \longrightarrow {{c{n^{\rm{2}}}} \over {g(n)}} \ge {\rm{1}}\buildrel {n \ge {n_1}} \over \longrightarrow {{c{n^{\rm{2}}}} \over {c'n\;lg\;n}} \ge {\rm{1}}$
مثلا فرض کنید ${c^{\rm{'}}}$ برابر ۱۰۰۰ باشد و c برابر ۱ باشد $(1000n~\lg~n?{n^2})$، خب هر چقدر هم که بیشتر شدن مقدار n باعث بشود که ${n^2}$ رشدش از n lg n بیشتر بشود ولی زورش به ۱۰۰۰ نمیرسد، پس برای این که ${n^2}$ بزرگتر بشه از $1000n~\lg~n$، باید n عدد بزرگی باشد. قرار شد $c'n\ lg\ n\le {cn}^{\mathrm{2\ }}$ باشد، حالا اگر c از ${c^{\rm{'}}}$ بزرگتر باشد که در این صورت $c{n^2}$ خیلی بهتر از $c'n\ lg\ n$ است ولی اگر c کوچکتر از ${c^{\rm{'}}}$ باشد، حالا وظیفه n است که با بزرگتر خودش، کوچکی c به ${c^{\rm{'}}}$ را جبران کند.
الف) ${(n+k)}^m\mathrm{=}\mathrm{\theta }\mathrm{(}n^m\mathrm{)}$، زمانی که k و m هر دو ثابت باشند.
ب) ${\mathrm{2}}^{n+\mathrm{1}}=O\mathrm{(}{\mathrm{2}}^n\mathrm{)}$ ج) ${\mathrm{2}}^{\mathrm{2}n+\mathrm{1}}=O\mathrm{(}{\mathrm{2}}^n\mathrm{)}$
${(n+k)}^m\mathrm{=}n^m\mathrm{+C}\mathrm{1^*\ }n^{m-\mathrm{1}}\mathrm{+...+}k^m\mathrm{=}\mathrm{\theta }\mathrm{(}n^m\mathrm{)}$
${\mathrm{2}}^{n+\mathrm{1}}=\mathrm{2}^\mathrm{*}{\mathrm{2}}^n=\mathrm{O(}{\mathrm{2}}^n\mathrm{)}$
در حالت کلی داریم: ${(\log n)^c} \lt {n^b} \lt {a^n} \lt n! \Leftarrow a,b,c \gt 1$
نمونه سوالات روابط بازگشتی درس ساختمان داده
$\\x = x + 1;$
ابتدا باید مرتبه زمانی هر دو برنامه را به دست بیارویم. برای برنامه A داریم:
$\lambda = 1 \Rightarrow n$ بار
$i = 2 \Rightarrow {n \over 2}$
$i = 3 \Rightarrow {n \over 3}$
$\cdot\qquad \Rightarrow n + {n \over 2} + {n \over 3} + ... + n \Rightarrow n(1 + {1 \over 2} + {1 \over 3} + ... + {1 \over n}) = \theta (n\log n)$
$\cdot$
$\cdot$
$i = 2 \Rightarrow {n \over 2}$
برای برنامه B داریم، $T(n) = 2T(n - 3) + n$ بنابر قضیه مستر مرتبه اجرای این برنامه برابر است با $\theta ({2^{{n \over 3}}})$
بنابر مفروضات مسئله داریم ${V_2} = {1 \over {128}}{V_1}$ حال با استفاده از رابطه ${{O({n_2})} \over {O({n_1})}} = {{{t_2}} \over {{t_1}}} \times {{{v_2}} \over {{v_1}}}$
${{{2^{{n \over 3}}}} \over {n\log n}} = {{{t_2}} \over {5m\,\sec }} \times {1 \over {128}}{{{V_1}} \over {{V_1}}} \Rightarrow {{{2^{{6 \over 3}}}} \over {32\log 32}} = {{{t_2}} \over {5m\,\sec }} \times {1 \over {{2^7}}} \Rightarrow {t_2} = {{{2^2} \times 5 \times {2^7}} \over {{2^5} \times 5}} = 16m\,\sec $
$T(n)\ =\frac{\ 2}{n}(T\left(0\right)+\ T\left(1\right)+T\left(2\right)+\ldots+T\left(n-1)\right)+n$
ابتدا رابطه اصلی را در n ضرب میکنیم و سپس در رابطه بدست آمده به جای n+1، n قرار میدهیم:
$nT(n)\ =2(T\left(0\right)+\ T\left(1\right)+T\left(2\right)+\ldots+T\left(n-1)\right)+n^2\ (\ast)$ $(n+1)T(n+1)\ =2(T\left(0\right)+\ T\left(1\right)+T\left(2\right)+\ldots+T\left(n)\right)+({n+1)}^2\ (\ast\ast)$
سپس رابطه $(\ast \ast)$ را از منفی رابطه $(\ast)$ میکنیم:
$\left(n\mathrm{+1}\right)T\left(n\mathrm{+1}\right)\mathrm{-}nT\left(n\right)\mathrm{=2}T\left(n\right)\mathrm{+2}n\mathrm{+1}\mathrm{\to }\left(n\mathrm{+1}\right)T\left(n\mathrm{+1}\right)\mathrm{=}\left(n\mathrm{+2}\right)T\left(n\right)\mathrm{+2}n\mathrm{+1}$
$T\left(n\mathrm{+1}\right)=\frac{\left(n\mathrm{+2}\right)T\mathrm{(}n\mathrm{)}}{n\mathrm{+1}}\mathrm{+}\frac{\mathrm{2}n\mathrm{+1}}{\left(n\mathrm{+1}\right)}{{\stackrel{\text{تقسیم}\mathrm{\ }\text{میکنیم }\mathrm{\ }\mathrm{n+2}\mathrm{\ }\text{طرفین }\mathrm{\ }را\mathrm{\ }\text{بر}\mathrm{\ }}{\longrightarrow}}}\frac{T\mathrm{(}n\mathrm{+1)}}{n\mathrm{+2}}=\frac{T\mathrm{(}n\mathrm{)}}{\left(n\mathrm{+1}\right)}\mathrm{+}\frac{\mathrm{2}n\mathrm{+1}}{\left(n\mathrm{+1}\right)\left(n\mathrm{+2}\right)}$
حال اگر تابع $g(n) = \frac{T(n)}{n+1}$ را به این صورت تعریف کنیم، با توجه به رابطه بازگشتیای که در بالا بدست آوردیم خواهیم داشت:
$g\left(n+1\right)\mathrm{=}g\left(n\right)\mathrm{+}\frac{\mathrm{2}n\mathrm{+1}}{\left(n\mathrm{+1}\right)\left(n\mathrm{+2}\right)}\stackrel{اگر\mathrm{\ }\text{این}\mathrm{\ }\text{رابطه}\mathrm{\ }\text{بازگشتی}\mathrm{\ }را\mathrm{\ }\text{باز}\mathrm{\ }\text{کنیم}\mathrm{\ }\text{خواهیم}\mathrm{\ }\text{داشت}}{\longrightarrow}$
$g\left(n+1\right)\mathrm{=}\frac{\mathrm{2}n\mathrm{+1}}{\left(n\mathrm{+1}\right)\left(n\mathrm{+2}\right)}\mathrm{+}\frac{\mathrm{2}n\mathrm{-}\mathrm{1}}{\mathrm{(}n\mathrm{)(}n\mathrm{+1)}}\mathrm{+\dots +}\frac{\mathrm{3}}{\mathrm{2\times 3}}\mathrm{\ +}g\mathrm{(1)}$
$\mathrm{\to }g\left(n+1\right)\mathrm{=}\left(\mathrm{2}n\mathrm{+1}\right)\left(\frac{\mathrm{1}}{n\mathrm{+1}}\mathrm{-}\frac{\mathrm{1}}{n\mathrm{+2}}\right)\mathrm{+\dots +3}\left(\frac{\mathrm{1}}{\mathrm{2}}\mathrm{-}\frac{\mathrm{1}}{\mathrm{3}}\right)\mathrm{+}g\left(\mathrm{1}\right)$
$= g\left(n+1\right)\mathrm{=\ }\left(\frac{\left(\mathrm{2}n\mathrm{+1}\right)}{n\mathrm{+1}}\mathrm{-}\frac{\left(\mathrm{2}n\mathrm{+1}\right)}{n\mathrm{+2}}\right)\mathrm{+\ }\left(\frac{\left(\mathrm{2}n\mathrm{-}\mathrm{1}\right)}{n}\mathrm{-}\frac{\left(\mathrm{2}n\mathrm{-}\mathrm{1}\right)}{n\mathrm{+1}}\right)\mathrm{+\ \dots \ +}\left(\frac{\mathrm{3}}{\mathrm{2}}\mathrm{-}\frac{\mathrm{3}}{\mathrm{3}}\right)\mathrm{+}g\left(\mathrm{1}\right)\mathrm{\ }$
$\mathrm{=2}\left(\frac{\mathrm{1}}{n\mathrm{+1}}\mathrm{+}\frac{\mathrm{1}}{n}\mathrm{+\dots +}\frac{\mathrm{1}}{\mathrm{3}}\right)\mathrm{+\ }\frac{\mathrm{3}}{\mathrm{2}}\mathrm{-}\frac{\mathrm{2}n\mathrm{+1}}{n\mathrm{+2}}\mathrm{=}O\left(logn\right)\mathrm{\to }T\left(n\right)\mathrm{=}O\left(nlogn\right)$
واضح است که گزینه 3 از $O(n^2)$ است و گزینه 1و 4 نیز $O(n)$ .
می دانیم که گزینه دوم $\omega (\sqrt n)$ زیرا اگر به رابطه دقت کنید، در سمت راست تساوی داریم، $\sqrt n×99×T(\sqrt n)+100 × n$ ، از طرفی به کمک حدس زدن نشان خواهیم داد که:
${Suppose}:\ {T}\left({n}\right)\sim{n}^{k}$ ${T}\left({n}\right)=\sqrt{n}\times\sqrt{\mathbf{99}\times{T}\left(\sqrt{n}\right)+\mathbf{100}}$ $\sqrt{n}\times\sqrt{\mathbf{99}\times{T}\left(\sqrt{n}\right)+\mathbf{100}}\ \ \sim\sqrt{n}\times\sqrt{\mathbf{99}\times{n}^\frac{{k}}{\mathbf{2}}+\mathbf{100}}$ ${n}^{k}\sim\sqrt{n}\times{n}^\frac{{k}}{\mathbf{4}}$ ${k}=\frac{\mathbf{1}}{\mathbf{2}}+\frac{{k}}{\mathbf{4}}\rightarrow{k}=\frac{\mathbf{2}}{\mathbf{3}}$ ${T}\left({n}\right)\sim{O}\left({n}^\frac{\mathbf{2}}{\mathbf{3}}\right)$
روش دوم:
${Suppose}:\ {T}\left({n}\right)\sim{{cn}}^\frac{\mathbf{2}}{\mathbf{3}}$
جایگذاری کنید:
$\sqrt{n}\times\sqrt{\mathbf{99}\times{{cn}}^\frac{\mathbf{1}}{\mathbf{3}}+\mathbf{100}}\le{c}{n}^\frac{\mathbf{2}}{\mathbf{3}}\ ~\ {c}{n}^{\frac{\mathbf{1}}{\mathbf{2}}+\frac{\mathbf{1}}{\mathbf{6}}}\le{c}{n}^\frac{\mathbf{2}}{\mathbf{3}}$
$n\lg n||n^{2} ||n^{2} \lg ^{2} n||n^{3} $
با استفاده از قضیه مستر میدانیم که:
برای عبارت $T(n)=aT(\frac{n}{b})+f(n),\ a\ge 1,b>1$ مرتبه سه حالت داریم:
$1- \ \ n^{{{log}_b a\ }}>f\left(n\right)\Rightarrow T\left(n\right)\ \epsilon \ \theta \left(n^{{{log}_b a\ }}\right)$
$2-\ \ n^{{{log}_b a\ }} \lt f\left(n\right)\Rightarrow T\left(n\right)\ \epsilon \ \theta \left(f\left(n\right)\right)$
$3-\ \ n^{{{log}_b a\ }}=f\left(n\right)\Rightarrow T(n)\ \epsilon \ \theta (f\left(n\right)*log(n))$
نکته) اگر در $f(n)$، هر توانی از $lg(n)$ را کنار میگذاریم و بخش باقیمانده از آن را با سمت چپ مقایسه میکنیم سه حالت رخ میدهد
4- اگر سمت چپ بزرگتر باشد مرتبه برابر سمت چپی میشود
5- اگر سمت راستی بزرگتر باشد، مرتبه برابر با سمت راستی ضرب در $lgn$ (یعنی همون $f(n)$) خواهد بود.
6- اگر برابر باشند مرتبه برابر با $f(n)$ ضرب در $lgn$ میشود
حال برای عبارت بالا داریم $ n^{{{log}_3 9\ }}=n^2\ ?\ f\left(n\right) $ در نتیجه برای اینکه این شرط برقرار باشد باید به صورت زیر عمل کنیم و هر تابع را امتحان کرده و $f(n)$ پیدا کنیم که شرط $\mathrm{T}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\epsilon }\mathrm{\ }\mathrm{\theta }\left(\mathrm{g}\left(\mathrm{n}\right)\right)$ برقرار میسازد.
$\mathrm{T}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\epsilon }\mathrm{\ }\mathrm{\theta }\left(n\ lg\left(\mathrm{n}\right)\right)\mathrm{\Rightarrow }\text{وجود}\mathrm{\ }\text{ندارد}$ $\mathrm{T}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\epsilon }\mathrm{\ }\mathrm{\theta }\left({\mathrm{n}}^2\right){{\stackrel{f(n)=n}{\Longrightarrow}}}{\mathrm{n}}^{\mathrm{2}}\mathrm{>n}\mathrm{\Rightarrow }\mathrm{T}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\epsilon }\mathrm{\ }\mathrm{\theta }\left({\mathrm{n}}^{\mathrm{2}}\right)$ $\mathrm{T}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\epsilon }\mathrm{\ }\mathrm{\theta }\left({\mathrm{n}}^2l{\mathrm{g}}^2n\right){{\stackrel{f(n)={\mathrm{n}}^2l\mathrm{g\ }n}{\Longrightarrow}}}{\mathrm{n}}^2\mathrm{=}{\mathrm{n}}^2\mathrm{\Rightarrow }\mathrm{T}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\epsilon }\mathrm{\ }\mathrm{\theta }\left({\mathrm{n}}^2l{\mathrm{g}}^2n\right)$ $\mathrm{T}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\epsilon }\mathrm{\ }\mathrm{\theta }\left({\mathrm{n}}^3\right){{\stackrel{f(n)=n}{\Longrightarrow}}}{\mathrm{n}}^{\mathrm{3}}\mathrm{>n}\mathrm{\Rightarrow }\mathrm{T}\left(\mathrm{n}\right)\mathrm{\ }\mathrm{\epsilon }\mathrm{\ }\mathrm{\theta }\left({\mathrm{n}}^{\mathrm{3}}\right)$
${\rm{f(A,i)}}$ $~~~~\{ $ ${\qquad\rm{if(A[i] + i}} \le {\rm{n) }}$ ${\qquad\qquad\qquad\rm{return f(A , A[i] + i);}}$ ${\qquad\rm{return ~1;}}$ $~~~~\} $
برای این سوال درخت بازگشتی را رسم میکنیم.
جمع
$\qquad~~~~\qquad\qquad n\qquad\qquad\qquad~~ \Rightarrow n$

$\qquad~~~~~~\qquad\alpha {n \over 2}\qquad\qquad(1 - \alpha ){n \over 2}\qquad~~~~~~\Rightarrow n$

${\alpha ^2}{n \over 4} + (1 - \alpha )\alpha {n \over 4}\qquad\qquad(1 - \alpha )\alpha {n \over 4}\qquad\qquad{(1 - \alpha )^2}{n \over 4} \Rightarrow {n \over 4}$
$ \Rightarrow\text{ جمع } n + {n \over 2} + {n \over 4} + {n \over 8} + ... \Rightarrow n(1 + {1 \over 2} + {1 \over 4} + {1 \over 8} + ...) \Rightarrow 2n \Rightarrow O(n)~~~~~~~~~~$
تصاعد هندسی با جمله اول 1 و قدرت نسبت $ \Leftarrow a \times {{{q^n} - 1} \over {q - 1}} \Leftarrow {1 \over 2}$ اگر n خیلی زیاد باشد.
${a \over {1 - q}} \Rightarrow {1 \over {{1 \over 2}}} = 2$
$for({\mathop{\rm int}}\,i = 1;j \le n;j + = i)$
$\\x = x + 1;$
ابتدا باید مرتبه زمانی هر دو برنامه را به دست بیارویم. برای برنامه A داریم:
$\lambda = 1 \Rightarrow n$ بار
$i = 2 \Rightarrow {n \over 2}$ $i = 3 \Rightarrow {n \over 3}$ $\cdot\qquad \Rightarrow n + {n \over 2} + {n \over 3} + ... + n \Rightarrow n(1 + {1 \over 2} + {1 \over 3} + ... + {1 \over n}) = \theta (n\log n)$ $\cdot$ $\cdot$ $i = 2 \Rightarrow {n \over 2}$
برای برنامه B داریم، $T(n) = 2T(n - 3) + n$ بنابر قضیه مستر مرتبه اجرای این برنامه برابر است با $\theta ({2^{{n \over 3}}})$
بنابر مفروضات مسئله داریم ${V_2} = {1 \over {128}}{V_1}$ حال با استفاده از رابطه ${{O({n_2})} \over {O({n_1})}} = {{{t_2}} \over {{t_1}}} \times {{{v_2}} \over {{v_1}}}$
${{{2^{{n \over 3}}}} \over {n\log n}} = {{{t_2}} \over {5m\,\sec }} \times {1 \over {128}}{{{V_1}} \over {{V_1}}} \Rightarrow {{{2^{{6 \over 3}}}} \over {32\log 32}} = {{{t_2}} \over {5m\,\sec }} \times {1 \over {{2^7}}} \Rightarrow {t_2} = {{{2^2} \times 5 \times {2^7}} \over {{2^5} \times 5}} = 16m\,\sec $
int Test (int n, int k)
{
${\rm{int\,i = \circ;}}$ $if(k > \circ )i = n;$ $Test( - - n, - - k);$ $cout \ll i \ll "," \ll k \ll ",";$ }
نمونه سوالات درختها درس ساختمان داده
Preorder: fgbceda
Postorder: gedcabf
| 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | |
| $A~$ | 80 | 35 | 52 | 30 | 23 | 48 | 49 | 21 | 12 | 1 | 2 |
اعداد ۵ تا ۱۲ را در نظر بگیرید که !۸ جایگشت دارند. اگر عدد ۵ یا ۱۲ زودتر از 4 تا 11 وارد شوند حتماً 5 در ۱۲ با هم مقایسه میشوند. تعداد حالاتی که 5 زودتر وارد شود !7 و تعداد حالاتی که ۱۲ زودتر وارد شود نیز !7 است پس:
$\text{احتمال}=\frac{\mathrm{2\times 7!}}{\mathrm{8!}}\mathrm{=}\frac{\mathrm{1}}{\mathrm{4}}$
درج هر عنصر در ساختمان داده Red-Black Tree یا منجر به تغییر رنگ میشود و یا حداکثر ۲ دوران انجام میشود.
20 ,26 ,22 ,24 ,23 ,10 ,15 ,6 ,5 :PostOrder
با توجه به این که پیمایش inorder یک درخت BST صعودی است با داشتن دو پیمایش inorder و preorder درخت قابل ترسیم است.
20 ,26 ,22 ,24 ,23 ,10 ,15 ,6 ,5: Post
26 ,24 ,23 ,22 ,20 ,15 ,10 ,6 ,5: In
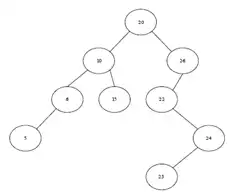
با توجه به مفروضات مسئله ریشه در عمق صفر قرار دارد. همان طور که در شکل زیر نشان داده شده است بیش ترین عمق درخت برابر با ۹ میباشد.
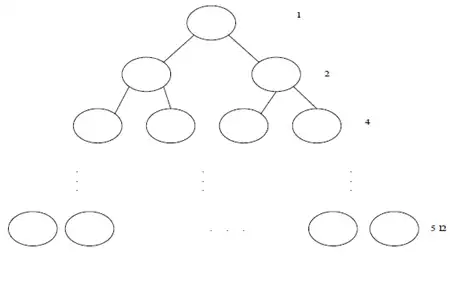
در یک درخت باینری کامل هر سطح شامل 2i گره میباشد (همچنین هر گره در سطح i دارای عمق i و ارتفاع h-i میباشد) حال میخواهیم مجموعه تمامی ارتفاعها را حساب کنیم.
$S\mathrm{=}\sum\limits_{i = \circ}^h {} {{\mathrm{2}}^i\mathrm{(}h\mathrm{-}i\mathrm{)}\mathrm{\Rightarrow }S\mathrm{=}h\mathrm{+}\mathrm{2}\mathrm{(h-}\mathrm{1}\mathrm{)+}\mathrm{4}\mathrm{(h-}\mathrm{2}\mathrm{)+...\ +}{\mathrm{2}}^{\mathrm{h-}\mathrm{1}}\mathrm{(}\mathrm{1}\mathrm{)}}$
حال طرفین را در 2 ضرب میکنیم
$\mathrm{2}S\mathrm{=2}\mathrm{h+}\mathrm{4}\mathrm{(h-}\mathrm{1}\mathrm{)+}\mathrm{8}\mathrm{(h-}\mathrm{2}\mathrm{)+...\ +}{\mathrm{2}}^{\mathrm{h}}\mathrm{(}\mathrm{1}\mathrm{)}$
حال S را از رابطهی 2S-S بدست میآوریم
$\mathrm{2}S\mathrm{-}S\mathrm{=}\mathrm{-h+}\mathrm{2}\mathrm{+}\mathrm{4}\mathrm{+...+}{\mathrm{2}}^{\mathrm{h}}\mathrm{\Rightarrow }S\mathrm{=(}{\mathrm{2}}^{\mathrm{h}\mathrm{+1}}\mathrm{-}\mathrm{1}\mathrm{)-}\mathrm{(h-}\mathrm{1}\mathrm{)}$
با توجه به این که مجموع تمامی گرهها در یک درخت کامل برابر n است داریم ${\mathrm{n=}\mathrm{2}}^{\mathrm{h}\mathrm{+1}}\mathrm{-}\mathrm{1}$ بنابراین داریم $\mathrm{h=log(n}\mathrm{+1}\mathrm{)}$ در نهایت با جایگذاری داریم
$S\mathrm{=}\mathrm{n-(h}\mathrm{-}\mathrm{1}\mathrm{)}\mathrm{\Rightarrow }O\mathrm{(}n\mathrm{-}log~n\mathrm{)}\mathrm{\Rightarrow }O\mathrm{(}n\mathrm{-}h\mathrm{)}$
الف) حداکثر تعداد گرههای یک درخت دودویی با L برگ
ب) حداقل و پ) حداکثر تعداد گرههای یک درخت دودویی محض با ارتفاع h (درختی که هر گره آن یا فرزند ندارد یا دو فرزند دارد.) درختها
ب) حداقل تعداد گرههای یک درخت دودویی محض با ارتفاع h زمانی رخ میدهد که درخت شبیه یک مسیر باشد که از هر گرهی آن یک فرزند اضافه نیز خارج شده باشد. در این صورت تعداد گرههای هر سطح ۲ است که به علاوه گرهی ریشه تعداد کل گرهها برابر ۱+ h2 خواهد بود.
پ) حداقل تعداد گرههای یک درخت دودویی محض با ارتفاع h زمانی رخ میدهد که درخت پر باشد که یک درخت پر با ارتفاع h دارای ${2^{h + 1}} - 1$ گره میباشد.
نمونه سوالات مرتب سازی درس ساختمان داده
راه حل 1 عدد گذاری)
با توجه به اینکه گزینه ها رابطه دقیقی از n داده اند کافیست برای n=2 چک کنیم و گزینه صحیح را پیدا کنیم:
برای n=2 و یک مجموعه دو عضوی، بیشترین تعداد زوج معکوس به صورت A=[max min] خواهد بود (جای max و min عدد هم میتوانید بذارید مثلا A = [25 14]) در نتیجه بیشترین تعداد زوج معکوسی برابر با 1 است و فقط گزینه 1 صحیح است.
راه حل 2 اثبات)
به توضیحات زیر توجه کنید:
وارونگی نسبت به صعودی بودن:
وقتی یک آرایه داریم و برای دو عنصر A[i] , A[j] با جایگاه (اندیس) به ترتیب i, j شرط زیر برقرار است میگوییم که یک وارونگی (زوج- معکوس بر اساس این تست یا inversion) داریم.
$j \gt i but A[i] \gt A[j]$
برای پیدا کردن وارونگی ها از سمت چپ به راست، حرکت میکنیم تمامی عناصری که از یک عنصر کوچکتر هستند با آن عنصر وارونه هستند.
مثال) آرایه زیر چند وارونگی دارد:
$\mathrm{A}\left[\mathrm{1\dots 5}\right]\mathrm{=}\left[\mathrm{12\ 4\ 9\ 7\ 5}\right]$
وارونگی ها:
$\left(12,4\right)\left(12,9\right)\left(12,7\right)\left(12,5\right) \\ \left(9,7\right)\left(9,5\right) \\ \left(7,5\right)$
در کل 7 وارونگی داریم.
نکته) آرایه صعودی وارونگی ندارد.
نکته) آرایه نزولی max تعداد وارونگی دارد.
راه اثبات 1)
چون هر عنصر با تمامی عناصر بعدش وارونگی دارد پس تعداد وارونگی آرایه نزولی برابر است با
$\underbrace{n-1}_{\text{تعداد}\mathrm{\ }\text{عناصر}\mathrm{\ }\text{بعد }\mathrm{\ }\text{از }\mathrm{\ }\text{عنصر}\mathrm{\ }\text{اول}}+\underbrace{n-2}_{\text{تعداد }\mathrm{\ }\text{عناصر}\mathrm{\ }\text{بعد }\mathrm{\ }\text{از }\mathrm{\ }\text{عنصر}\mathrm{\ }\text{اول}\mathrm{\ }}+\cdots +1+\underbrace{0}_{\text{عنصر}\mathrm{\ }\text{آخر}\mathrm{\ }}=\frac{n\left(n-1\right)}{2}$
دقت کنید تعداد وارونگی ها را دوبار نشمارید برای مثال عنصر آخر با تمامی عناصر قبل از خودش وارونگی دارد اما چون در محاسبه $n-1$ قبلی این وارونگی ها به حساب آورده ایم نباید $n-1$ وارونگی هم برای عنصر آخر جمع کنیم.
راه اثبات 2)
هر دو عنصری که انتخاب کنیم چون آرایه نزولی است قطعا شرط j > i but A[i] > A[j] برقرار است پس تعداد وراونگی برابر تعداد انتخاب بدون ترتیب دو عنصر از n عنصر است.
$\left( \begin{array}{c} n \\ 2 \end{array} \right)=\frac{n(n-1)}{2}$
موارد گفته شده را در آرایه نزولی زیر میتوانید امتحان کنید.
$A\left[1\dots 4\right]=\left[12\ 8\ 5\ 3\ 1\right]$
نکته) متوسط تعداد وارونگی ها در یک آرایه برابر با $\frac{n(n-1)}{4}$ است.
اثبات:
روش 1:
فرض کنید L یک لیست دلخواه از عناصر است و $L_R$ لیستی با عناصر L است که به صورت برعکس چیده شده است برای مثال:
$L=\left[b\ e\ f\ a\ g\right]\ ,\ L_R=[g\ a\ f\ e\ b]$
حالا دو عضو از لیست L انتخاب میکنیم، برای این کار $\left( \begin{array}{c}n \\ 2 \end{array} \right)$ حالت وجود دارد. دو عضوی که انتخاب کردیم در حداقل یکی از لیست های $L$ یا $L_R$ با یکدیگر وارونگی دارند. بنابراین میتوان نتیجه گرفت در دو لیست $L$ و $L_R$ در مجموع $\left( \begin{array}{c} n \\ 2 \end{array} \right)$ وارونگی وجود دارد.
حال برای اعضای هر لیستی $n!$ جایگشت وجود دارد که این تعداد جایگشت را به دو مجموعه ی مجزا که یکی شامل $L$ ها و دیگری شامل $L_R$ ها است تقسیم میکنیم (به عبارت دیگر نصفی از جایشگت ها برعکس شده ی نصفه ی دیگر هستند). در نتیجه میتوان فهمید که میانگین وارونگی ها در کل جایشگت های برابر است با $\frac{\frac{n(n-1)}{2}}{2}=\frac{n(n-1)}{4}$.
روش 2 (استقرا):
در استقرا ابتدا برای تعدادی عدد کوچک درستی قضیه $P(n)$ را چک میکردیم و سپس قضیه را برای $P(k)$ درست فرض میکردیم و برای $P(k+1)$ درستی آن را اثبات میکردیم. برای قضیه "تعداد میانگین وارونگی برابر است با $\frac{\frac{n(n-1)}{2}}{2}=\frac{n(n-1)}{4}$" ابتدا برای آرایه ای با n=1 آن را چک میکنیم سپس برای P(K) ان را اثبات میکنیم. (اثبات کامل را در این لینک میتوانید مطالعه کنید)
نکته) زمان اجرا الگوریتم مرتب سازی درجی مستقیماً به تعداد وارونگی ها بستگی دارد و اگر آرایه وارونگی داشته باشد زمان اجرای مرتب سازی درجی برابر $(\theta (n+1))$ است.
نکته) با مرتب سازی درجی و ادغامی میتوان تعداد وارونگی ها شمرد.
نحوه شمردن مرتب سازی درجی:
در الگوریتم مرتب سازی درجی یک شمارنده اضافه میکنیم. هر جابهجایی که انجام شد یکی به شمارنده اضافه میکنیم به معنی اینکه هر این جابهجایی به دلیل یک وارونگی بوده که به وسیله الگوریتم حل شده.
یاددآوری:
در مرتب سازی درجی هربار از عنصر دوم شروع میکنیم هر عنصر را در انتهای آرایه درج میکنیم با عناصر قبلی مقایسه میکنیم اگر جایشان درست نبود باید جابهجایی انجام میدادیم برای مثال:
$\mathrm{A}\left[\mathrm{1\dots 5}\right]\mathrm{=}\left[\mathrm{12\ 4\ 9\ 7\ 5}\right]$
ابتدا 4 را درج میکنیم پس جایش باید با 12 تغییر کند. $[4 \ 12]$
سپس 9 را درج میکنیم و دوباره 9 جایش را با 12 تغییر میدهد. $[4 \ 9 \ 12]$
7 را درج میکنیم به ترتیب جایش با 12 و 9 تغییر میدهد. $[4 \ 7 \ 9 \ 12]$
5 را درج میکنیم جایش را با 12، 9 و 7 تغییر میدهد. $[4 \ 5 \ 7 \ 9 \ 12]$
در مجموع 7 جابهجایی و در نتیجه 7 وارونگی داشتیم.
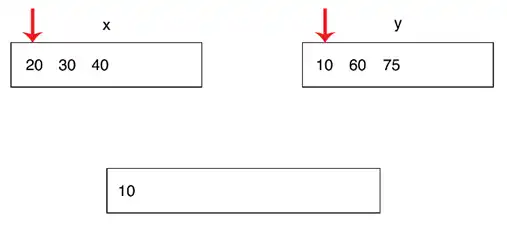
نحو شمردن مرتب سازی ادغامی:
در این الگوریتم نیز یک کانتر میگذاریم. و هر وقت کسی از لیست $y$ انتخاب شد کانتر را با تعداد تمامی عناصر موجود در لیست $x$ جمع میزنیم و این کار را در تمامی مراحل مرتب سازی ادغامی انجام میدهیم. ( از مقایسه آرایه های کوچک شده و تک عنصری تا آخرین مرحله.)
بنابر صورت سوال به رابطه بازگشتی زیر میرسیم.
$T(n)=T(\frac{n}{\mathrm{4}})+T(\frac{\mathrm{3} n}{\mathrm{4}})+O(n)$
که با استفاده از تئوری مستر و یا درخت مرتبه اجرا برابر با $(n~log~n)O$ میشود.
$A)\ O\left(log\right)\ \ \ B)\ O\left(n\right)\ \ \ \ C)\ O\left(n~log~n\right)\ \ \ D)~O~(n^\mathrm{2})$
P) انتخابی Q) مرتبسازی درجی R) جستوجوی دودویی S) جستوجوی ادغامی
مرتبه اجرا در بهترین حالت برای مرتبسازی انتخابی برابر با $O~(n^\mathrm{2})$ ادغامی برابر $O\left(n~log~n\right)$، مرتبسازی درجی برابر $O~(n)$ و جستوجوی دودویی برابر $\ O\left(log\ n\right)$میباشد.
مرتب بودن دو طرف عنصر P[i] استفاده از ایده جستوجوی دودویی را فراهم میکند. در واقع میتوانیم مشابه الگوریتم جستوجوی دودویی عمل کنیم ولی جهت جستوجو را سه عنصر وسط آرایه تعیین میکنند. با مقایسه عنصر وسط آرایه با عناصر قبل و بعدش، یکی از سه حالت زیر رخ خواهد داد:
- حالت اول: $\mathrm{P[}\frac{n}{\mathrm{2}}\mathrm{-}\mathrm{1}\mathrm{]}\mathrm{>P[}\frac{n}{\mathrm{2}}\mathrm{]>P[}\frac{n}{\mathrm{2}}+\mathrm{1}\mathrm{]}$ در این حالت باید جستوجو را در نیمه اول آرایه $\mathrm{P[1..}\frac{n}{\mathrm{2}}\mathrm{-}\mathrm{1}\mathrm{]}$ ادامه دهیم.
- حالت دوم: $\mathrm{P[}\frac{n}{\mathrm{2}}\mathrm{-}\mathrm{1}\mathrm{]}\mathrm{ \lt P[}\frac{n}{\mathrm{2}}\mathrm{] \lt P[}\frac{n}{\mathrm{2}}+\mathrm{1}\mathrm{]}$ در این حالت باید جستوجو را در نیمه دوم آرایه $\mathrm{P[}\frac{n}{\mathrm{2}}\mathrm{+}\mathrm{1..}\mathrm{n}\mathrm{]}$ ادامه دهیم.
- حالت اول: $\mathrm{P[}\frac{n}{\mathrm{2}}\mathrm{-}\mathrm{1}\mathrm{]}\mathrm{ \lt P[}\frac{n}{\mathrm{2}}\mathrm{]>P[}\frac{n}{\mathrm{2}}+\mathrm{1}\mathrm{]}$
در این حالت اندیس مورد جستوجو پیدا شده است و پاسخ مسئله میباشد.
بنابراین در هر فاز الگوریتم، یا پاسخ مسئله را به دست میآوریم و یا باید در یکی از نیمههای آرایه به جستوجو را ادامه دهیم. پس اگر T(n) تابع پیچیدگی زمانی این الگوریتم باشد، رابطه بازگشتی آن به صورت زیر خواهد بود:
$\mathrm{T(n)\ =T(}\frac{n}{\mathrm{2}}\mathrm{)\ +}\mathrm{\circleddash }\mathrm{(}\mathrm{1}\mathrm{)}$
که مرتبه زمانی این رابطه بازگشتی O(lgn) میباشد، یعنی در بدترین حالت مرتبه الگوریتم $\ominus(lgn)$ است.
برای به دست آوردن کران پایین این مسئله، محاسبات را از دید درخت تصمیمگیری این مسئله نگاه میکنیم. هر گرهی داخلی این درخت از یک جفت کوزه (یک قرمز و یک سبز) که مقایسه میکنیم تشکیل شده است و دارای سه یال خروجی دارد. (کوزهی قرمز ظرفیت کمتر، ظرفیت برابر و یا ظرفیت بیشتر نسبت به کوزهی سبز). برگهای این درخت، گروهبندیهای یکتای کوزهها را نشان میدهد. ارتفاع درخت تصمیم این مسئله برابر تعداد مقایسههای الگوریتم در بدترین است. تعداد برگهای این درخت برابر !n میباشد چون هر جایگشت از کوزههای قرمز به همراه کوزهی سبز متناظرش یک نتیجه متفاوت را حاصل میکند. هر شاخه درخت از درجه ۳ میباشد و بنابراین این درخت حداکثر ${3^h}$ برگ خواهد داشت. بنابراین خواهیم داشت:
${\mathrm{3}}^h\ge n !\Rightarrow h\ge {log}_{\mathrm{3}}(n!)\Rightarrow h\mathrm{\in }\mathrm{\Omega }(n\ lg\ n)$
نمونه سوالات جداول درهم ساز درس ساختمان داده
| 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 | 0 |
| 33 | 46 | 52 | 34 | 23 | 42 |
چه تعداد از دنبالههای متفاوت درج کلیدها در این جدول وجود دارد که جدول بالا را نتیجه میدهد؟
جداول درهم سازنمونه سوالات آرایه، جستجو در آرایه، لیست پیوندی، پشته، صف درس ساختمان داده
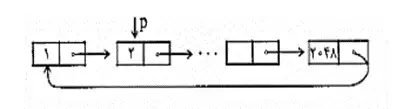
struct node
{
int value;
struct node * next;
};
void rearrange(struct node * list)
{
struct node * p, * q;
int temp;
if ((!list) || !list -> next)
return;
p=list; q=list-> next;
while(q)
{
temp = p-> value;
p-> value= q-> value;
q-> value= temp;
q=-> next;
p=p ? q-> next:. ;
}
}
ABCDEFGH
برای گزینه ۱ ابتدا B و A را داخل پشته قرار میدهیم و بلافاصله میخوانیم، چون مقدار pop صفر است دو عنصر بالای پشته فراخوانی میشود سپس D و C را داخل پشته قرار میدهیم و دوباره pop میکنیم، چون مقدار pop فرد است فقط مقدار D بر میگردد و دوباره عمل push برای F و E انجام و بلافاصله pop که دو عنصر بالا را بر میگرداند و سپس مجددا pop که فقط یک عنصر بر میگرداند و در نهایت H و push ،G میشود و دوباره pop میشود و گزینه ۱ در نهایت تولید میشود.
برای مورد ۲ داریم:
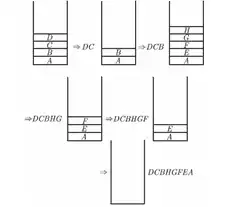
برای مورد 4 داریم:
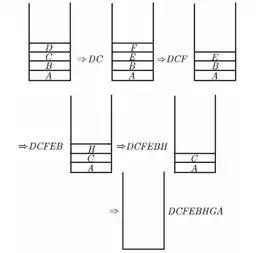
فقط برای گزینه 3 نمیتوان رسم کرد چون DC با هم آمده که امکانپذیر بنابر مسئله نمیباشد.
نمونه سوالات ساختمان داده این صفحه از چه منابعی است؟
در این صفحه از نمونه سوالات ساختمان داده کرمن، نمونه سوالات امتحانی ساختمان داده دانشگاه تهران، نمونه سوالات ساختمان داده دانشگاه شریف، نمونه سوالات استخدامی درس ساختمان داده، نمونه سوالات ساختمان داده با جواب دانشگاه ازاد و همین طور سوالات ساختمان داده کنکور ارشد و دکتری رشته های مختلف از جمله کامپیوتر و آی تی و علوم کامپیوتر استفاده شده است.
آیا نمونه سوالات ساختمان داده این صفحه جواب دارد و به درد چه کسانی میخورد؟
بله. تمامی سوالات ساختمان داده این صفحه با پاسخ های کاملا تشریحی در اختیار شما قرار گرفته است. سوالات این صفحه به درد دانشجویان مقطع لیسانس رشته های مختلف، داوطلبان کنکورهای مقاطع مختلف از جمله ارشد و دکتری، داوطلبان آزمون های استخدامی و افرادی است که به دنبال حل مسائل بیشتر برای مسلط شدن روی ساختمان داده هستند

































