

برای شروع حرفهای کنکور ارشد کامپیوتر،آیتی و علوم کامپیوتر حتما روی عکس زیر کلیک کنید تا در کانال کنکور کامپیوتر عضو شوید، در این کانال به معرفی بهترین منابع کنکور ارشد،برنامه ریزی و مشاوره، معرفی گرایشها و هر آنچه برای موفقیت در کنکور ارشد نیاز دارید پرداخته شده است

امروزه به دلیل حضور غیرقابل انکار کامپیوترها، تلفنهای همراه هوشمند و ماشینها در زندگی انسان، واژه حافظه به گوش همه ما کاملا آشنا است. تصور کلی ما از حافظه در وسایل دیجیتالی وسیلهای است که ما در آن برنامهها، عکسها و اطلاعات و ویدیوها و ... را ذخیره میکنیم تا در آینده هنگام کار مجددا به آنها دسترسی پیدا کنیم و از آن استفاده کنیم. حقیقت این است که شاید این تصور شرح دقیق وظیفه حافظه نباشد اما تعریف درستی را از آن ارائه میدهد.
در این مقاله قصد داریم به همه جوانب حافظه از جمله انواع حافظه کامپیوتر، حافظه جانبی و کش و ... بپردازیم تا هم برای کسانی که قصد پیدا کردن یک دیدگاه کلی از حافظه را دارند مفید باشد و هم علاقهمندانی که میخواهند نحوه عملکرد حافظه را بدانند، از آن استفاده کنند.
حافظه کامپیوتر چیست؟
ما میدانیم که وظیفه پردازنده در کامپیوتر اجرای دستوراتیست که منجر به اجرای برنامه میشود اما سوال اینجاست که این دستورات در کجا قرار داشته و پس از اجرا به کجا منتقل میشوند؟
هر برنامه از خطوط زیادی کد تشکیل شده که برای اجرای آن برنامه، آن خطوط میبایست اجرا شوند. دستورات برنامه در حافظه قرار داشته و برای اجرا به پردازنده (CPU)پردازنده (CPU) چیست؟ بررسی انواع، وظایف و کاربردها سی پی یو قلب کامپیوتر و کامپیوتر قلب دنیای کنونی است، بنابراین در این صفحه به معرفی و بررسی سیپییو یا همان پردازنده مرکزی (CPU) پرداخته شده، و بطور کامل توضیح دادهایم که CPU از چه بخش هایی تشکیل شده و هر بخش چه وظایف و مشخصاتی دارد. منتقل میشوند در واقع پردازنده دستورات ذخیره شده در حافظه اصلی را خوانده و اجرا میکند؛ بنابراین پردازندهها به صورت دائمی با حافظه که از مهمترین المانهای معماری کامپیوتر آموزش جامع معماری کامپیوتر
سی پی یو قلب کامپیوتر و کامپیوتر قلب دنیای کنونی است، بنابراین در این صفحه به معرفی و بررسی سیپییو یا همان پردازنده مرکزی (CPU) پرداخته شده، و بطور کامل توضیح دادهایم که CPU از چه بخش هایی تشکیل شده و هر بخش چه وظایف و مشخصاتی دارد. منتقل میشوند در واقع پردازنده دستورات ذخیره شده در حافظه اصلی را خوانده و اجرا میکند؛ بنابراین پردازندهها به صورت دائمی با حافظه که از مهمترین المانهای معماری کامپیوتر آموزش جامع معماری کامپیوتر در مهندسی کامپیوتر، معماری کامپیوتر مجموعهای از قوانین و روشهایی است که به چگونگی طراحی، کارکرد، سازماندهی و پیاده سازی (ساخت) سیستمهای کامپیوتری میپردازد، در این صفحه به بررسی و آموزش کامل معماری کامپیوتر پرداخته شده است محسوب میشود در ارتباط هستند. در واقع اگر بخواهیم تعریف حافظه کامپیوتر را بیان کنیم میگوییم به محل ذخیره سازی داده ها و دستورات کامپیوتر حافظه گفته میشود.
در مهندسی کامپیوتر، معماری کامپیوتر مجموعهای از قوانین و روشهایی است که به چگونگی طراحی، کارکرد، سازماندهی و پیاده سازی (ساخت) سیستمهای کامپیوتری میپردازد، در این صفحه به بررسی و آموزش کامل معماری کامپیوتر پرداخته شده است محسوب میشود در ارتباط هستند. در واقع اگر بخواهیم تعریف حافظه کامپیوتر را بیان کنیم میگوییم به محل ذخیره سازی داده ها و دستورات کامپیوتر حافظه گفته میشود.
لازم به ذکر است که در سازمان ورودی و خروجی کامپیوتربررسی و آموزش ورودی و خروجی های کامپیوتر در این صفحه به معرفی ورودی و خروجی کامپیوتر و بررسی انواع دستگاه های ورودی و خروجی کامپیوتر نظیر کارت گرافیک، اسکنر و ... پرداخته شده است
، برخی از انواع حافظه کامپیوتر مانند هارد دیسک و فلش، هم ورودی محسوب میشوند و هم خروجی. این دستگاهها، برخی از زمانها نقش ورودی کامپیوتر و برخی از زمانهای دیگر نقش خروجی کامپیوتر را بازی میکنند.
در این صفحه به معرفی ورودی و خروجی کامپیوتر و بررسی انواع دستگاه های ورودی و خروجی کامپیوتر نظیر کارت گرافیک، اسکنر و ... پرداخته شده است
، برخی از انواع حافظه کامپیوتر مانند هارد دیسک و فلش، هم ورودی محسوب میشوند و هم خروجی. این دستگاهها، برخی از زمانها نقش ورودی کامپیوتر و برخی از زمانهای دیگر نقش خروجی کامپیوتر را بازی میکنند.
نرخ رشد سرعت حافظه در مقایسه با پردازندهها بسیار کندتر است. این امر به این معنی است که اختلاف سرعت پردازنده و حافظه به مرور زیادتر میشود. اشکالی که این امر ایجاد میکند این است که هر چقدر سرعت پردازنده زیاد باشد، اگر حافظهای که با آن کار میکند کند باشد، در عمل پردازنده مجبور است با حافظه همگام شود که این به معنی کاهش کارایی پردازنده است. بنابراین باید با استفاده از ترکیبی از سخت افزارسخت افزار چیست - بررسی اجزای اصلی سخت افزار کامپیوتر در این صفحه بررسی شده که سخت افزار چیست و سخت افزار کامپیوتر به زبان ساده معرفی شده است، همچنین به بررسی اجزای اصلی سخت افزار کامپیوتر پرداخته شده است و نرمافزار این اختلاف سرعت را تا حد امکان کاهش دهیم تا کارایی پردازنده کاهش نیابد. برای درک بهتر مثالی را بیان میکنیم تا توضیحات فوق ملموستر شوند.
در این صفحه بررسی شده که سخت افزار چیست و سخت افزار کامپیوتر به زبان ساده معرفی شده است، همچنین به بررسی اجزای اصلی سخت افزار کامپیوتر پرداخته شده است و نرمافزار این اختلاف سرعت را تا حد امکان کاهش دهیم تا کارایی پردازنده کاهش نیابد. برای درک بهتر مثالی را بیان میکنیم تا توضیحات فوق ملموستر شوند.
فرض کنید برنامهای وجود دارد که برای اجرا نیازمند 20 دقیقه استفاده از CPU و 40 دقیقه استفاده از حافظه است. حال اگر بخواهیم CPU را 10 برابر سریعتر کنیم، همان برنامه نیازمند 2 دقیقه CPU و 40 دقیقه حافظه است. با وجود اینکه CPU به میزان 10 برابر (!) سریعتر شده اما برنامهای که در ابتدا در 1 ساعت انجام میشد، حالا در 42 دقیقه انجام میشود که مشخص است که بهبود زیادی صورت نگرفته است در نتیجه بهترین روش، پیدا کردن راهکارهایی جهت افزایش سرعت حافظه است.
در این بخش میخواهیم این روشها را بررسی کنیم. برای این منظور نخست انواع حافظه ها اعم از انواع حافظه اصلی و انواع حافظه ثانویه را بررسی کرده، سپس به سلسله مراتب حافظه میپردازیم.
انواع حافظه کامپیوتر
به طور کلی ما دو نوع حافظه در کامپیوتر داریم. حافظه اصلی کامپیوتر و حافظه ثانویه کامپیوتر. تفاوت کلیدی بین حافظه اصلی و ثانویه سرعت دسترسی به آنهاست.
حافظه اصلی کامپیوتر
حافظه اصلی کامپیوتر شامل حافظه RAM و حافظه ROM است که در نزدیکی CPU و در داخل مادربرد کامپیوتر قرار گرفتهاند. نقش حافظه اصلی در خواندن سریع داده توسط CPU بسیار مهم است در نتیجه دادهها و دستوراتی که CPU به سرعت به آن نیاز دارد تا اجرا شوند در این حافظه ذخیره میشوند.
حافظه ثانویه کامپیوتر
حافظه ثانویه کامپیوتر در خارج از مادربرد کامپیوتر و در فضای دیگری دورتر از حافظه اصلی نسبت به CPU قرار دارد. حافظه ثانویه شامل هارد دیسک و حافظه SSD و ... است که به طور مستقیم یا از طریق شبکه به سیستم کامپیوتری متصل میشود. حافظه ثانویه نسبت به حافظه اصلی ارزانتر بوده و همچنین سرعت دسترسی کمتری نیز دارد. غالباً از این نوع از حافظه برای ذخیرهسازی دائمی اطلاعات استفاده میشود.
حافظه RAM و حافظه ROM
حافظهها از نظر دسترسی، به دو دسته حافظه با دسترسی ترتیبی (Sequential Access Memory) و حافظه با دسترسی تصادفی (Random Access Memory) تقسیم میشود. در حافظه با دسترسی ترتیبی برای دسترسی به یک داده، باید تمام دادهها از ابتدای حافظه تا آن داده خاص مورد دسترسی قرار بگیرد (مانند نوار کاست). در حافظه نوع دوم برای دسترسی به یک داده خاص مستقیماً به سراغ آن داده میرویم و به آن دسترسی پیدا میکنیم.
حافظههای با دسترسی تصادفی به دو دسته حافظه فقط خواندنی (Real Only Memory (ROM)) و حافظه خواندنی/نوشتنی (Read/Write Memory (RWM)) تقسیم میشوند.
در ROM فقط میتوان به دادههایی که از پیش در آن ذخیره شده است دسترسی داشت و امکان تغییر دادههای ذخیره شده در آن وجود ندارد. در حافظه RWM علاوه بر امکان خواندن داده از حافظه، امکان نوشتن داده در حافظه نیز وجود دارد. حافظه ROM یک حافظه غیرفرار (Non-Volatile) است، یعنی با قطع منبع تغذیه، اطلاعات داخل آن از بین نمیرود، ولی حافظه RWM (حافظه RAM) یک حافظه فرار (Volatile) است، یعنی با قطع منبع تغذیه اطلاعات داخل آن از بین میرود.
نکته: در بیشتر مراجع اصطلاح RAM و RWM را به صورت معادل به کار میبرند.
حافظه RAM معمولاً به دو صورت ایستا (Static) و پویا (Dynamic) وجود دارد. در حافظه ایستا هر سلول حافظه با استفاده از شش عدد ترانزیستور ساخته میشود، در حالی که در حافظه پویا هر سلول حافظه با استفاده از یک ترانزیستور و یک خازن ساخته میشود. شکل زیر ساختار یک سلول تکبیتی از این دو نوع حافظه را نشان میدهد.

در شکل (الف)، حافظه ایستا (SRAM)، با فعال شدن ورودی wr، اطلاعات موجود در ورودی d-in به داخل حافظه منتقل میشود و سپس توسط مسیر فیدبک توسط دو گیت Not در سلول حافظه باقی میماند (در واقع بیانگر سادهترین نوع لچ (Latch) در مدارهای منطقیآموزش مدار منطقی به زبان ساده - بررسی مدار منطقی و انواع آن امروزه درک صحیحی از مدارهای منطقی برای هر مهندس برق و کامپیوتر ضروری است. این مدارها عنصر اصلی کامپیوترها و بسیاری از وسایل الکترونیکی اطراف ما هستند، در این صفحه به بررسی و آموزش مدار منطقی پرداخته شده است است). اکنون با غیرفعال شدن ورودی rω، تعداد ورودی ذخیره شده در سلول حافظه همچنان باقی میماند. حال با فعال کردن ورودی rw میتوان مقدار ذخیره شده در حافظه را به خروجی d-out منتقل کرد.
امروزه درک صحیحی از مدارهای منطقی برای هر مهندس برق و کامپیوتر ضروری است. این مدارها عنصر اصلی کامپیوترها و بسیاری از وسایل الکترونیکی اطراف ما هستند، در این صفحه به بررسی و آموزش مدار منطقی پرداخته شده است است). اکنون با غیرفعال شدن ورودی rω، تعداد ورودی ذخیره شده در سلول حافظه همچنان باقی میماند. حال با فعال کردن ورودی rw میتوان مقدار ذخیره شده در حافظه را به خروجی d-out منتقل کرد.
در شکل (ب)، در سلول حافظه پویا (DRAM)، با فعال شدن سیگنال wr-rd مقدار ورودی io در خازن ذخیره میشود. سپس با غیرفعال کردن ورودی wr-rd مقدار ذخیره شده در خازن باقی میماند. برای مثال فرض کنید ورودی io برابر 1 باشد، با فعال کردن rω-rd این مقدار 1 به صورت بار در خازن ذخیره میشود.
حال با غیرفعال کردن wr-rd این شارژ در خازن باقی میماند. میتوان مقدار ذخیره شده در خازن را با فعال کردن wr-rd به خروجی سلول حافظه منتقل کرد. دقت کنید در این حالت ورودی و خروجیهای نوشتن و خواندن داده با هم ترکیب شدهاند و یک ورودی دو جهته (Bidirectional) برای خواندن/نوشتن داده داریم.
در سلول حافظه پویا معمولاً با غیرفعال شدن سیگنال wr-rd، به دلیل وجود مقاومتهای پارازیتی، مسیرهایی برای دشارژ خازن وجود دارد. این امر باعث میشود پس از مدتی محتویات (بار ذخیره شده) در خازن از بین برود. بنابراین در حافظه پویا باید در زمانهای مشخص، محتویات حافظه تازهسازی (Refresh) شود، عمل تازهسازی به معنی خواندن داده و بازنویسی مجدد آن است (شارژ دوباره خازن).
نکته: حافظه ایستا در مقایسه با حافظه پویا سرعت و هزینه بیشتری دارد.
سلسله مراتب حافظه (Memory Hierarchy)
سلسله مراتب حافظه از سطوح مختلف حافظه با گنجایش و سرعتهای متفاوت تشکیل شده است. در سطح اول (نزدیکترین سطح به پردازنده) حافظه نهان یا حافظه کش (cache) قرار دارد که سریعترین حافظه در سلسله مراتب حافظه است، پس از آن حافظه اصلی (Main Memory (MM)) قرار دارد که دارای گنجایش و سرعت متوسط است و پس از آن حافظه ثانویه (Secondary Storage) قرار دارد که پرگنجایشترین و کندترین حافظه در سلسله مراتب حافظه است. معمولاً حافظه ثانویه دیسک سخت (Hard Disk Drive (HDD)) نامیده میشود. شکل زیر این سلسله مراتب را نشان میدهد.

هر چقدر در سلسله مراتب حافظه به سمت پایین حرکت کنیم (از پردازنده دور شویم) گنجایش زیادتر، سرعت کمتر و هزینه در هر بایت کاهش مییابد. هدف از سلسله مراتب حافظه این است که وقتی از بیرون به سیستم حافظه نگاه میکنیم، حافظهای با سرعتی معادل سرعت حافظه نهان (سریعترین المان سیستم حافظه) و با گنجایشی معادل گنجایش HDD (پرگنجایشترین المان سیستم حافظه) ببینیم.
این امر با استفاده از ترکیب سختافزار و نرمافزار مناسب و به دلیل وجود اصل محلی بودن (Locality) در برنامهها امکانپذیر است. در ادامه با ذکر چند تعریف، سلسله مراتب حافظه را توضیح میدهیم.
اصل محلی بودن در کامپیوتر
معمولاً برنامهها در هر زمان به بخش کوچکی از فضای آدرسدهی خود دسترسی دارند. این امر را محلی بودن ارجاعها (Locality of Reference) میگوییم. معمولاً محلی بودن ارجاعها به صورت زمانی و مکانی وجود دارد.
- محلی بودن زمانی (Temporal Locality) : اگر پردازنده به یک خانه حافظه رجوع کرد، با احتمال زیاد مجدداً در زمان آینده نزدیک به آن رجوع خواهد کرد.
- محلی بودن مکانی (Spatial Locality) : اگر پردازنده به یک خانه حافظه رجوع کرد، با احتمال زیاد در زمان آینده نزدیک به خانههای مجاور آن نیز رجوع خواهد کرد.
حافظه کش چیست؟

همانطور که پیشتر اشاره شد، حافظه نهان سریعترین و گرانترین قیمت المان حافظه در سلسله مراتب حافظه است. حافظه نهان از سلولهای ایستا (SRAM) تشکیل شده است و زمان دسترسی آن معمولاً در حدود 1 سیکل ساعت است، یعنی پردازنده میتواند در یک سیکل به داده مورد نظر خود در cache دسترسی پیدا کند.
در صورتی که این داده در cache پیدا نشود به سراغ حافظه اصلی میرویم و این امر مستلزم صرف زمان نسبتاً زیادی است (حدوداً 10 برابر زمان دسترسی cache). این جریمهای است که باید بابت عدم موفقیت دسترسی به cache بپردازیم از این رو به آن جریمه عدم برخورد (Miss Penalty) میگویند.
وقتی پردازنده آدرس یک خانه حافظه را جهت ارجاع تولید میکند، در ابتدا در cache به دنبال این آدرس میگردیم، در صورتی که داده مورد نظر در cache پیدا شد، با سرعت بالا در اختیار در پردازنده قرار میگیرد. در غیر این صورت به سراغ سطح بعدی سلسله مراتب حافظه میرویم.
در صورت پیدا شدن داده در این سطح (حافظه اصلی) داده در اختیار پردازنده قرار میگیرد. در غیر این صورت به سراغ سطح بعدی سلسله مراتب حافظه میرویم و این امر به همین شکل ادامه پیدا میکند. در نتیجه متوجه میشویم که علت وجود کش، بالا بردن سرعت دسترسی پردازنده به دستورات ذخیره شده در حافظه است.
در صورت موفقیتآمیز بودن دسترسی به cache، میگوییم hit رخ داده است. به عبارت دیگر اگر داده مورد نظر در cache پیدا شود، میگوییم Hit رخ داده است. در صورت عدم موفقیت دسترسی به cache، میگوییم Miss رخ داده است. به عبارت دیگر اگر داده مورد نظر در cache پیدا نشود، میگوییم Miss رخ داده است.
اکنون پرسش اساسی که مطرح میشود این است که چگونه میتوان فهمید داده مورد نظر در cache وجود دارد یا خیر. این امر توسط مکانیزم نگاشت (Mapping) انجام میشود. برای فهم بهتر مطلب، سناریوی دسترسی به حافظه توسط پردازنده را با هم مرور میکنیم.
پردازنده برای دسترسی به یک داده، آدرس حافظه اصلی را تولید میکند (در حقیقت پردازنده آدرس مجازی را تولید میکند و این آدرس به آدرس فیزیکی ترجمه میشود. ولی در اینجا با کمی چشمپوشی فرض میکنیم پردازنده آدرس حافظه فیزیکی یا همان حافظه اصلی را تولید میکند) بدون این که از وجود cache آگاه باشد.
در این لحظه cache یک کپی از آدرس را برداشته و به این پرسش پاسخ میدهد که آیا داده متناظر این آدرس در cache وجود دارد یا خیر (به عبارت دیگر آیا hit رخ داده است یا خیر). بنابراین این مکانیزم نگاشت در حقیقت یک تابع است که ورودی آن آدرس حافظه اصلی و خروجی آن یک بیت است که نشان میدهد این داده در cache وجود دارد یا خیر. برای این منظور سه نگاشت مختلف وجود دارد که در ادامه توضیح داده میشود.
نرخ برخورد (Hit Rate) در حافظه کش
نسبت تعداد دسترسیهای موفق به cache به تعداد کل دسترسیهای به حافظه را نرخ برخورد میگوییم.
\[\mathrm{Hit\ Rate\ =\ }\frac{\mathrm{\#\ }\mathrm{of\ Hits}}{\mathrm{\#\ }\mathrm{of\ Memory\ Accesses}}\]
نرخ عدم برخورد (Miss Rate) در حافظه کش
نسبت دسترسیهای ناموفق به cache به تعداد کل دسترسیهای به حافظه را نرخ عدم برخورد میگوییم.
\[\mathrm{Miss\ Rate\ =\ }\frac{\mathrm{\#\ }\mathrm{of\ Misses}}{\mathrm{\#\ }\mathrm{of\ Memory\ Accesses}}\]
رابطه بین نرخ برخورد و عدم برخورد به صورت زیر است:
Hit Rate = 1 - Miss Rate
زمان دسترسی موثر به حافظه
فرض کنید در سلسله مراتب حافظه یک cache با نرخ برخورد hc و زمان دسترسی tc و یک حافظه اصلی با زمان دسترسی tm داریم. اگر بخواهیم زمان دسترسی مؤثر (متوسط زمان دسترسی به حافظه) را پیدا کنیم، باید نحوهی دسترسی به حافظه را بدانیم.
کلاً دو روش دسترسی به حافظه وجود دارد، روش سری و روش موازی. در روش سری ابتدا به سراغ cache میرویم و در صورت پیدا نشدن داده در cache، به سراغ حافظه اصلی میرویم. در روش موازی دسترسی به cache و حافظه اصلی به صورت همزمان شروع میشوند (یعنی زمان دسترسی به cache و حافظه اصلی با هم، همپوشانی (overlap) دارند).
زمان دسترسی مؤثر در حالت سری:
\[{\mathrm{t}}_{\mathrm{eff}}\mathrm{=}{\mathrm{t}}_{\mathrm{c}}\mathrm{+}\left(\mathrm{1}\mathrm{-}{\mathrm{h}}_{\mathrm{c}}\right){\mathrm{t}}_{\mathrm{m}}\]
زمان دسترسی مؤثر در حالت موازی:
\[{\mathrm{t}}_{\mathrm{eff}}\mathrm{=}{\mathrm{h}}_{\mathrm{c}}{\mathrm{t}}_{\mathrm{c}}\mathrm{+}\left(\mathrm{1}\mathrm{-}{\mathrm{h}}_{\mathrm{c}}\right){\mathrm{t}}_{\mathrm{m}}\]
از آنجا که hit یا miss شدن دسترسی، به صورت احتمالاتی است، بنابراین میتوان برای به دست آوردن زمان دسترسی مؤثر از درخت احتمالات استفاده کرد.
مثال: فرض کنید سلسله مراتب حافظه از یک cache و یک حافظه اصلی تشکیل شده است. تأخیر و نرخ برخورد cache به ترتیب برابر 1ns و 0.98 و تأخیر حافظه اصلی برابر 10ns باشد زمان دسترسی مؤثر را در دو حالت سری و موازی به دست آورید.
حالت اول: استفاده از فرمولهای بالا
سری: \[{\mathrm{t}}_{\mathrm{eff}}\mathrm{=}\mathrm{1}\mathrm{ns\ +\ }\left(\mathrm{1}\mathrm{-}\mathrm{0.98}\right)\mathrm{*}\mathrm{10}\mathrm{ns\ =\ }\mathrm{1.2}\mathrm{ns}\]
موازی: \[{\mathrm{t}}_{\mathrm{eff}}\mathrm{=}\mathrm{0.98}\mathrm{\ \times \ }\mathrm{1}\mathrm{ns\ +\ }\left(\mathrm{1}\mathrm{-}\mathrm{0.98}\right)\mathrm{10}\mathrm{ns\ =\ }\mathrm{1.18}\mathrm{n}\mathrm{s}\]
حالت دوم: استفاده از درخت احتمالات
در درخت احتمالات، یالها نشاندهنده احتمال یک رویداد و برگها نتیجه حاصل از آن رویداد است. زمان دسترسی مؤثر از ضرب احتمال رویدادها در نتیجه رویدادها و محاسبه مجموع به دست میآید.

نکته: زمان دسترسی در حالت موازی از زمان دسترسی در حالت سری بهتر است.
نکته: توان مصرفی روش دسترسی موازی به دلیل دسترسی همزمان به cache و حافظه اصلی بیشتر از توان مصرفی روش دسترسی سری است.
مثال: در یک سیستم حافظه 3 سطح حافظه با زمانهای دسترسی t3,t2,t1 و نرخ برخورد h2,h1 و 1 داریم. زمان دسترسی مؤثر را در دو حالت سری و موازی حساب کنید.

نگاشت حافظه پنهان
همانطور که گفته شد، پردازنده برای دسترسی به یک داده، آدرس حافظه اصلی را تولید میکند؛ بدون این که از وجود cache آگاه باشد. در این لحظه cache یک کپی از آدرس را برداشته و به این پرسش پاسخ میدهد که آیا داده متناظر این آدرس در cache وجود دارد یا خیر (به عبارت دیگر آیا hit رخ داده است یا خیر). بنابراین این مکانیزم نگاشت در حقیقت یک تابع است که ورودی آن آدرس حافظه اصلی و خروجی آن یک بیت است که نشان میدهد این داده در cache وجود دارد یا خیر. برای این منظور سه نگاشت مختلف وجود دارد.
نگاشت مستقیم (Direct Mapping)
در این روش هر خانه حافظه اصلی فقط میتواند به یک خانه خاص از cache نگاشت شود (معمولاً به یک خانه cache یک بلوک (Block) گفته میشود). بنابراین برای به دست آوردن شماره بلوک cache از رابطه زیر استفاده میکنیم.
(تعداد بلوکهای cache) mod (آدرس) = شماره بلوک در cache
مثال: فرض کنید در یک سیستم حافظه، گنجایش حافظه اصلی 32 کلمه و گنجایش کش (Cache)، 4 بلوک باشد. برای دنباله آدرسهای زیر شماره بلوک متناظر در cache را به دست آورید.
| - | شماره بلوک در cache | آدرس |
|---|---|---|
| \[\mathrm{\circ }\mathrm{\ \ \ \ \ }\mathrm{mod\ \ \ \ \ }\mathrm{4}\mathrm{\ =\ }\mathrm{\circ }\] | 0 | 0 |
| \[\mathrm{2}\mathrm{\ \ \ \ \ }\mathrm{mod\ \ \ \ \ }\mathrm{4}\mathrm{\ =\ }\mathrm{2}\] | 2 | 2 |
| \[\mathrm{5}\mathrm{\ \ \ \ \ }\mathrm{mod\ \ \ \ \ }\mathrm{4}\mathrm{\ =\ }\mathrm{1}\] | 1 | 5 |
| \[\mathrm{4}\mathrm{\ \ \ \ \ }\mathrm{mod\ \ \ \ \ }\mathrm{4}\mathrm{\ =\ }\mathrm{1}\] | 0 | 8 |
| \[\mathrm{8}\mathrm{\ \ \ \ \ }\mathrm{mod\ \ \ \ \ }\mathrm{4}\mathrm{\ =\ }\mathrm{0}\] | 0 | 4 |
همانطور که دیده میشود، آدرسهای مختلفی از حافظه اصلی میتوانند به یک بلوک cache نگاشت شوند. یک راه سادهتر برای به دست آوردن شماره بلوک cache، به این صورت است که از سمت راست آدرس حافظه به تعداد خطوط آدرس cache جدا کنیم. به این بخش از آدرس، اندیس (Index) گفته میشود.
بخش اندیس، شماره بلوک متناظر با این آدرس را در cache مشخص میکند. به بخش باقیمانده آدرس برچسب (Tag) گفته میشود. بخش Tag آدرس وجه تمایز آدرسهای مختلفی است که به یک بلوک cache نگاشت میشود. برای مثال آدرس $\mathrm{\circ }\mathrm{\ =\ }\underbrace{\mathrm{\ }\mathrm{\circ }\mathrm{\circ }\mathrm{\circ }\mathrm{\ }}_{\mathrm{Tag}}\mathrm{\ }\underbrace{\mathrm{\ }\mathrm{\circ }\mathrm{\circ }\mathrm{\ }}_{\mathrm{Index}}\mathrm{\ }$ و $\mathrm{4}\mathrm{\ =\ }\underbrace{\mathrm{\circ }\mathrm{\circ }\mathrm{1}}_{\mathrm{Tag}}\mathrm{\ }\underbrace{\mathrm{\ }\mathrm{\circ }\mathrm{\circ }\mathrm{\ }}_{\mathrm{Index}}$ هر دو به بلوک $\mathrm{\circ }\mathrm{\circ }$ در cache نگاشت میشوند (چون اندیس هر دو $\mathrm{\circ }\mathrm{\circ }$ است) ولی Tag آدرس $\mathrm{\circ }$ برابر $\mathrm{\circ }\mathrm{\circ }\mathrm{\circ }$ و Tag آدرس 4 برابر $\mathrm{\circ }\mathrm{\circ }\mathrm{1}$ است. بنابراین میتوان ساختار cache، با نگاشت مستقیم را مطابق شکل زیر در نظر گرفت.

همانطور که در این شکل دیده میشود، هر بلوک cache علاوه بر کلمه داده دارای یک فیلد Tag و یک بیت V یا (Valid Bit) است. بیت V نشان میدهد که آیا در این بلوک cache داده معتبری قرار دارد یا خیر. برای این منظور در شروع کار، توسط کنترلر cache تمام بیتهای V برابر $\mathrm{\circ }$ میشوند تا نشان دهد در cache هیچ داده معتبری قرار ندارد.
با تولید یک آدرس توسط پردازنده، توسط اندیس آدرس به سراغ یک بلوک خاص cache میآییم. اگر $\mathrm{V\ =\ }\mathrm{\circ }$ باشد، نشاندهنده این است که در این بلوک داده معتبری قرار ندارد، در نتیجه Miss رخ میدهد (خروجی گیت AND $\mathrm{\circ }$ میشود). اگر 1 V = باشد فقط در صورتی hit رخ میدهد که فیلد Tag این بلوک، Tag آدرس یکسان باشد. بنابراین Miss رخ میدهد. مانند حالت قبل، M[22] از حافظه اصلی خوانده شده و یک کپی از آن در بلوک 10 در cache نوشته شده. فیلد Tag را با Tag آدرس جدید پر میکنیم.
با تولید آدرس 00011 = 3، به سراغ بلوک 11 در cache میرویم و مشابه حالت اول به دلیل $\mathrm{V\ =\ }\mathrm{\circ }$، Miss رخ میدهد. شکل (د) محتویات cache را پس از این دسترسی نشان میدهد. به دلیل مشابه دسترسی به آدرس 5 سبب بروز Miss میشود.شکل (هـ) محتویات cache را پس از این دسترسی نشان میدهد. در دسترسی به آدرس $\mathrm{\circ }\mathrm{\circ }\mathrm{\circ }\mathrm{\circ }\mathrm{\circ }$، با توجه به $\mathrm{\circ }\mathrm{\circ }$ بودن اندیس در بلوک $\mathrm{\circ }\mathrm{\circ }$ در کش، V=1 است و Tag آدرس با فیلد Tag یکسان است بنابراین Hit رخ میدهد. به همین شکل برای دو دسترسی بعدی نیز میتوان تشخیص داد که Miss رخ میدهد. 
بنابراین از 7 دسترسی به حافظه فقط 1 مورد آن در cache پیدا شد. بنابراین:
\[\mathrm{Hit\ Rate\ =\ }\frac{\mathrm{1}}{\mathrm{7}}\]
نکته: در برخی از پردازندهها (مانند MIPS) برای آدرسدهی به صورت کلمه و بایت دو بیت سمت راست آدرس را به عنوان افست بایت (Byte offset) در نظر میگیرند. در این صورت از بیت سوم به بعد، به تعداد خطوط آدرس cache جدا کرده و آن را اندیس نامیده و بقیه بیتها را نیز Tag مینامیم.
نکته: سربار حافظه cache به بیتهایی گفته میشود که برای مدیریت نگاشت یک آدرس در cache به ساختار cache اضافه میشود.
مثال: فرض کنید خطوط آدرس در یک حافظه 32 بیتی است. در این حافظه توانایی آدرسدهی بایت و کلمه وجود دارد. اگر فرض کنید گنجایش cache برابر 4096 بلوک است، میزان سربار cache را محاسبه کنید.
با توجه به این که گنجایش cache برابر $\mathrm{4096}\mathrm{\ =\ }{\mathrm{2}}^{\mathrm{12}}$ بلوک است، بنابراین تعداد خطوط آدرس cache (که تعیینکننده تعداد بیتهای اندیس است) برابر 12 بیت میشود. بنابراین از 32 بیت آدرس، 2 بیت سمت راست به عنوان افست بایت و 12 بیت بعدی به عنوان اندیس استفاده میشود. در نتیجه $\mathrm{32}\mathrm{-}\mathrm{12}\mathrm{-}\mathrm{2}\mathrm{\ =\ }\mathrm{18}$ بیت برای Tag باقی میماند. (شکل زیر را ببینید)

میزان سربار cache به ازاء هر بلوک عبارتست از: 1 بیت برای V و 18 بیت برای Tag. بنابراین میزان کل سربار cache برابر است با:
\[{\mathrm{2}}^{\mathrm{12}}\mathrm{\times }\left(\mathrm{18}\mathrm{\ +\ }\mathrm{1}\right)\mathrm{=}\mathrm{76}\mathrm{\ kbit}\]
نگاشت کاملا انجمنی Fully Associative
بزرگترین ایراد روش نگاشت مستقیم این است که اگر تمام خانههای cache خالی باشند ولی برنامه به صورت متوالی دو آدرسی را تولید کند که به یک بلوک cache نگاشت میشوند، همیشه Miss رخ میدهد. برای رفع این مشکل روش کاملاً شرکتپذیر یا انجمنی ارائه میشود که در آن هر آدرس حافظه اصلی میتواند به هر بلوک cache نگاشت شود.
به عبارت دیگر در اینجا اندیس وجود ندارد که به یک بلوک خاص cache اشاره کند و فقط آن بلوک برای داده مورد نظر جستجو شود. به تعبیر دیگر مسئله این است که تمام آدرس به عنوان Tag در نظر گرفته میشود و تمام cache (تمام بلوکهای cache) باید به صورت موازی جستجو شود. شکل زیر ساختار کاملاً انجمنی را برای cache نشان میدهد.

همانطور که در شکل دیده میشود، به دلیل وجود تعداد زیادی مقایسهکننده (به تعداد بلوکهای cache) این روش بسیار پرهزینه است. از این رو این روش برای cacheهای با اندازهی بزرگ خیلی مناسب نیست.
همانطور که دیده میشود کل آدرس به عنوان Tag برای مقایسه به cache داده میشود و تمام بلوکهای cache به صورت همزمان جستجو میشوند، در صورتی که یکی از بلوکها اعلام برابری کند (Hit رخ دهد) داده متناظر این بلوک توسط مالتی پلکسر به خروجی منتقل میشود.
در غیر این صورت (در صورتی که Miss رخ دهد) مانند حالت نگاشت مستقیم داده مورد نظر از حافظه اصلی خوانده شده در اختیار پردازنده گذاشته میشود و یک کپی از آن نیز در cache قرار میگیرد. در اینجا این کپی در اولین بلوک خالی cache قرار داده میشود. در صورتی که هیچکدام از بلوکهای cache خالی نباشد، باید یکی از بلوکهای cache را خارج کرده و این داده جدید را جایگزین آن کنیم.
به انتخاب یک کاندید برای جایگزینی، اصطلاحاً سیاست جایگزینی (Replacement Policy) گفته میشود. سیاست جایگزینی معمولاً به صورت FIFO یا LRU (Least Recently Used) است. در FIFO اولین بلوکی که وارد cacheشده است را از cache خارج می کنیم. در LRU بلوکی که اخیراً کمتر به آن دسترسی انجام شده است را از cache خارج میکنیم.
مثال: برای یک سیستم حافظه با همان مشخصات مثال نگاشت مستقیم و استفاده از یک cache کاملاً شرکتپذیر، نرخ برخورد را به دست آورید.
| نرخ برخورد |
|---|
| \[\mathrm{\circ }\mathrm{\ \ \ =\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ \ \ M}\] |
| \[\mathrm{22}\mathrm{=}\mathrm{1}\mathrm{\circ }\mathrm{11}\mathrm{\circ }\mathrm{\ \ M}\] |
| \[\mathrm{3}\mathrm{\ \ =\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{11}\mathrm{\ \ \ \ M}\] |
| \[\mathrm{5}\mathrm{\ \ =\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{1}\mathrm{\circ }\mathrm{1}\mathrm{\ \ \ M}\] |
| \[\mathrm{\circ }\mathrm{\ \ \ =\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ \ \ M}\] |
| \[\mathrm{12}\mathrm{=\ }\mathrm{\circ }\mathrm{11}\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ \ M}\] |
| \[\mathrm{22}\mathrm{=}\mathrm{1}\mathrm{\circ }\mathrm{11}\mathrm{\circ }\mathrm{\ \ M}\] |
با تولید آدرس 1$\mathrm{\circ }$11$\mathrm{\circ }$= 22، تمام بلوکهای cache به صورت موازی جستجو میشوند. در سه بلوک داده معتبری وجود ندارد (0=V) و در دیگری Tag آدرس یا فیلد Tag یکسان نیست بنابراین Miss رخ میدهد. در ادامه مشابه حالت قبل عمل میکنیم (شکل (ج) را ببینید)، به همین ترتیب برای دو آدرس بعدی نیز Miss رخ میدهد و در نهایت cache به شکل (د) در میآید. با دسترسی به آدرس $\mathrm{\circ }$، داده متناظر آن در cache پیدا میشود و Hit رخ میدهد.
با تولید آدرس $\mathrm{12}\mathrm{=\ }\mathrm{\circ }\mathrm{11}\mathrm{\circ }\mathrm{\ }\mathrm{\circ }$، در cache، Miss رخ میدهد ولی مشکل این جا است که هیچ بلوک خالی در cache وجود ندارد، بنابراین باید یکی از بلوکهای موجود را از Cache خارج کنیم چون سیاست جایگزینی انتخابی LRU است، بنابراین باید ببینیم اخیراً کدام بلوک کمتر مورد دسترسی قرار گرفته است. بین چهار انتخاب 22، 3، 5 و $\mathrm{\circ }$ آدرس 22 اخیراً کمتر مورد استفاده قرار گرفته است، در نتیجه از cache خارج شده و آدرس 12 جایگزین آن میشود (شکل (هـ) را ببینید). در نهایت برای آدرس 1$\mathrm{\circ }$ 1$\mathrm{\circ }$1 = 22 تیر Miss رخ میدهد.

نگاشت مجموعهای انجمنی (Set-Associative)
همانطورکه اشاره شد روش نگاشت کاملاً انجمنی دارای هزینه بالایی است. برای اینکه در این هزینه صرفهجویی شود روش مجموعهای انجمنی ارائه شده است که ترکیبی از دو روش قبلی است. به این صورت که cache از تعدادی مجموعه تشکیل شده است که در داخل هر مجموعه تعدادی بلوک وجود دارد.
در ابتدا توسط بخشی از آدرس (اندیس) یک مجموعه انتخاب میشود و سپس در داخل این مجموعه تمام بلوکها به صورت موازی جستجو میشوند. اگر در داخل یک مجموعه، m عدد بلوک وجود داشته باشد به این cache، m-way Set-Associative گفته میشود. برای مثال در شکل روبهرو یک cache با 8 بلوک به صورت way-2 سازماندهی شده است. در نتیجه 4 مجموعه داریم که در هر مجموعه 2 بلوک قرار دارد.

بخش اندیس از حافظه، شماره مجموعه را مشخص میکند و در داخل مجموعه عمل جستجو به صورت موازی انجام میشود. مجموعه داریم که در هر مجموعه 2 بلوک قرار دارد. بخش اندیس از حافظه، شماره مجموعه را مشخص میکند و در داخل مجموعه عمل جستجو به صورت موازی انجام میشود.
مثال: فرض کنید یک پردازنده آدرسهای $\mathrm{\circ }$ تا 8 را سه بار متوالی تولید میکند. اگر یک cache با گنجایش 8 کلمه در اختیار داشته باشیم در هر یک از حالتهای زیر نرخ برخورد چقدر است؟
(الف) cache با نگاشت مستقیم
(ب) cache کاملاً شرکتپذیر با سیاست جایگزینی FIFO
(ج) cache مجموعهای شرکتپذیر با 2 بلوک در هر مجموعه با سیاست جایگزینی FIFO
قسمت الف:

در این حالت، در ابتدا cache خالی است بنابراین برای 8 دسترسی اول Miss رخ میدهد. آدرس 8 دارای اندیس $\mathrm{\circ }\mathrm{\ }\mathrm{\circ }\mathrm{\ }\mathrm{\circ }$ است بنابراین به بلوک $\mathrm{\circ }$ نگاشت میشود. از آنجا که بلوک $\mathrm{\circ }$ در حال حاضر حاوی M[0] است، بنابراین Miss رخ میدهد و M[8] جایگزین آن میشود. مجدداً با تولید آدرس $\mathrm{\circ }$، Miss رخ میدهد و M[0] در بلوک $\mathrm{\circ }\mathrm{\ }\mathrm{\circ }$ جایگزین M[8] میشود.
حال دسترسیهای بعدی 1 تا 7 درون cache وجود دارد، بنابراین Hit رخ میدهد. مجدداً با تولید آدرس 8 همان اتفاق قبلی رخ میدهد. بنابراین داریم:
\[\mathrm{Hit\ Rate\ =\ }\frac{\mathrm{2}\mathrm{\ \times \ }\mathrm{7}}{\mathrm{3}\mathrm{\ \times \ }\mathrm{9}}\mathrm{=}\frac{\mathrm{14}}{\mathrm{27}}\]
قسمت ب:

در ابتدا cache خالی است، بنابراین 8 دسترسی اول سبب بروز Miss میشوند. دسترسی به آدرس 8 چون در cache پیدا نمیشود سبب بروز Miss میشود و چون سیاست جایگزین FIFO است اولین دادهای که وارد cache شده است یعنی $\mathrm{M}\left[\mathrm{\circ }\right]$ را از cache خارج میکند و خودش جایگزین آن میشود.
حال دسترسی به $\mathrm{M}\left[\mathrm{\circ }\right]$، اولین داده وارد شده به cache $\left(\mathrm{M}\left[\mathrm{1}]\right.\right)$ را خارج میکند و خودش جایگزین آن میشود. حال دسترسی به $\mathrm{M}\left[\mathrm{1}]\right.$ سبب خارج شدن $\mathrm{M}\left[\mathrm{2}]\right.$، دسترسی به $\mathrm{M}\left[\mathrm{2}]\right.$ سبب خارج شدن $\mathrm{M}\left[\mathrm{3}]\right.$ و ... می شود. بنابراین برای تمام دسترسی ها Miss داریم. یعنی:

در ابتدا cache خالی است و 8 دسترسی اول سبب بروز Miss میشوند در این حالت محتویات cache به صورت زیر است (دقت کنید cache به صورت 4 مجموعه 2 بلوکی سازماندهی شده است).
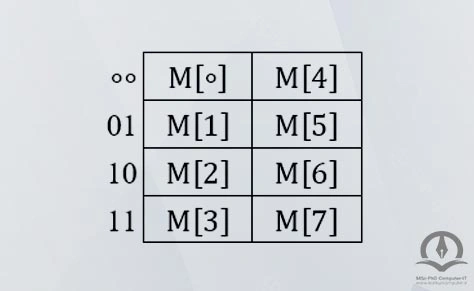
دسترسی به آدرس 8، در مجموعه $\mathrm{\circ }\mathrm{\circ }$ نگاشت میشود و از آنجا که داده $\mathrm{M}\left[\mathrm{8}\right.$ در این مجموعه وجود ندارد بنابراین Miss رخ میدهد. در نتیجه $\mathrm{M}\left[\mathrm{8}\right.$ باید در مجموعه $\mathrm{\circ }\mathrm{\circ }$ جایگزین بلوکی شود که زودتر وارد cache شده است، یعنی $\mathrm{M}\left[\mathrm{\circ }\right.$. با دسترسی به آدرس $\mathrm{\circ }$ این وضعیت تکرار شده و $\mathrm{M}\left[\mathrm{\circ }\right.$ جایگزین $\mathrm{M}\left[\mathrm{4}\right.$ میشود. برای دسترسیهای بعدی 1 , 2 , 3 ، Hit رخ میدهد. برای دسترسی $\mathrm{M}\left[\mathrm{4}\right.$ Miss رخ میدهد و $\mathrm{M}\left[\mathrm{8}\right.$ از cache خارج شده $\mathrm{M}\left[\mathrm{4}\right.$ جایگزین آن میشود و این امر به همین شکل ادامه پیدا میکند. بنابراین داریم:
\[\mathrm{Hit\ Rate\ =\ }\frac{\mathrm{2}\mathrm{\ \times \ }\mathrm{6}}{\mathrm{3}\mathrm{\ \times \ }\mathrm{9}}\mathrm{=}\frac{\mathrm{4}}{\mathrm{9}}\]
سیاست نوشتن در کش (Cache Writing Policy)
در تمام مواردی که تاکنون توضیح دادیم دسترسی به حافظه را به صورت دسترسی خواندن به حافظه در نظر گرفتهایم. اگر دسترسی به حافظه به منظور نوشتن باشد، اگر داده در cache موجود نباشد به سراغ حافظه اصلی رفته آن را تغییر میدهیم و یک کپی از آن داده را به cache منتقل میکنیم تا دسترسیهای بعد سریعتر انجام شود.
اگر داده در cache موجود باشد، کپی داده را در cache تغییر میدهیم. در این حالت کپی داده در cache و متناظر آن در حافظه اصلی برابر نیستند به این امر ناسازگاری cache (cache Inconsistency) میگوییم. برای حل کردن این ناسازگاری، از دو روش استفاده میشود.
روش Write-Through
در این روش به محض تغییر دادن یک داده در cache کپی آن را در حافظه اصلی تغییر میدهیم. این روش سبب کند شدن دسترسیهای نوشتن در حافظه میشود، زیرا به جای دسترسی در cache، دسترسی به حافظه اصلی انجام میشود.
یک راه برای حل کردن مشکل سرعت استفاده از یک بافر است، به این صورت که دادهای که در cache تغییر کرده است را به همراه آدرس مربوط به آن در بافر مینویسیم، سپس این دادهها به ترتیب در حافظه اصلی نوشته میشوند. به این ترتیب دیگر منتظر نوشتن در حافظه اصلی نمیشویم.
روش Write-Back
در این روش با تغییر دادن یک داده در cache، کپی آن در حافظه اصلی تغییر پیدا نمیکند. این تغییر وقتی در حافظه اصلی منعکس میشود که به هر دلیلی بخواهیم بلوک حاوی این داده تغییریافته را از cache خارج کنیم. این روش در مقایسه با روش قبل سرعت بهتری دارد ولی تا زمانی که داده به حافظه اصلی منتقل شود ناسازگاری cache وجود دارد.
حافظه مجازی Virtual Memory
از آنجا که برنامهنویس نمیداند برنامهاش در کجای حافظه اصلی بار (load) میشود، بنابراین آدرسهایی که در برنامه به کار میرود آدرسهای مجازی است. این آدرسهای مجازی باید به آدرسهای فیزیکی ترجمه شوند. این کار توسط یک جدول که در حافظه اصلی است انجام میشود. نام این جدول، جدول صفحه (Page Table) است. روال ترجمه یک آدرس مجازی در شکل زیر آمده است.

همانطور که در این شکل مشخص شده است، حافظه به یکسری بخشهای منطقی تقسیم شده است که به هر کدام از این بخشها یک صفحه (Page) گفته میشود. برای آدرسدهی یک خانه از حافظه، باید شماره صفحه و افست داخل صفحه را مشخص کرد.
حافظه (CAM) Content Addressable Memory
در حافظه معمولی با دادن آدرس به حافظه به محتویات یک خانه حافظه دسترسی پیدا میکنیم. شکل دیگری از حافظهها هستند که میتوان یک داده را به عنوان ورودی به آنها داد و حافظه مشخص میکند که آیا حاوی این داده است یا خیر. به عبارت دیگر حافظه این امکان را دارد که به صورت موازی تمام خانههای خود را جستجو کند و مشخص کند که این داده در کدامیک از خانههای حافظه وجود دارد.
یکی از کابردهای CAM در cache کاملاً شرکتپذیر است. شکل زیر ساختار یک CAM را نشان میدهد.

همانطور که در شکل دیده میشود AR و KR رجیسترهای n بیتی و MR رجیستر ${\mathrm{2}}^{\mathrm{k}}$ بیتی هستند. برای کار با این حافظه دادهای که می خواهیم در حافظه جستجو کنیم را در AR می نویسیم. رجیستر KR برای این منظور است که تعیین کنیم کدام بیت AR در جستجو دخالت کند و کدام بیت خیر. اگر بیت J ام KR $\mathrm{\circ }$ باشد یعنی بیت J ام AR در جستجو دخالت نمی کند در غیر این صورت باید روی بیت J ام AR عملیات جستجو انجام شود. به عبارت دیگر توسط KR میتوان عملیات جستجو را Mask کرد.
بیت i ام رجیستر MR وقتی 1 میشود که کلمه i ام در آرایه بیتها با رجیستر AR برابر باشد (بر اساس محتوای KR). کلمهی i ام از n بیت تشکیل شده است که باید تک تک بیتهای آن با بیتهای متناظر از رجیستر AR برابر باشد. ابتدا شرط برابری بیت J ام را مینویسیم.
\[{\mathrm{M}}_{\mathrm{i\ ,\ j}}\mathrm{=}\overline{{\mathrm{K}}_{\mathrm{j}}}\mathrm{+}{\mathrm{K}}_{\mathrm{j}}\left({\mathrm{A}}_{\mathrm{j}}{\mathrm{Q}}_{\mathrm{i\ ,\ j}}\mathrm{+}\overline{{\mathrm{A}}_{\mathrm{j}}{\mathrm{Q}}_{\mathrm{i\ ,\ j}}}\right)\]
\[{\mathrm{M}}_{\mathrm{i\ ,\ j}}\mathrm{=}\overline{{\mathrm{K}}_{\mathrm{j}}}\mathrm{+}{\mathrm{A}}_{\mathrm{j}}{\mathrm{Q}}_{\mathrm{i\ ,\ j}}\mathrm{+}\overline{{\mathrm{A}}_{\mathrm{j}}{\mathrm{Q}}_{\mathrm{i\ ,\ j}}}\]
در این رابطه مشخص است که بیت ${\mathrm{M}}_{\mathrm{i\ ,\ j}}$ وقتی 1 میشود که بیت J ام KR $\mathrm{\circ }$ باشد (یعنی بیت J ام Mask شده باشد) یا بیت J ام AR با بیت J ام سطر i ام آرایه بیتها برابر باشد (هر دو $\mathrm{\circ }$ یا هر دو 1 باشند).
حال برای این که بیت i ام Mr برابر ۱ باشد (یعنی کلمه i ام در حافظه) با AR برابر باشد، باید برای تمام بیتهای کلمه i ام ${\mathrm{M}}_{\mathrm{i\ ,\ j}}\mathrm{=}\mathrm{1}$ باشد. بنابراین داریم:
\[{\mathrm{M}}_{\mathrm{j}}\mathrm{=}\mathop{\mathop{\mathrm{AND}}^{\mathrm{n}\mathrm{-}\mathrm{1}}}_{\mathrm{j\ =\ }\mathrm{\circ }}\mathrm{\ \ \ \ }{\mathrm{M}}_{\mathrm{i\ ,\ j}}\]
برگ برگسازی حافظه (Memory Interleaving)
فرض کنید ماجولهای حافظه bit8 $\mathrm{\times}$ 256 در اختیار داریم و میخواهیم با استفاده از 4 عدد از این ماجولها یک حافظه bit8 $\mathrm{\times}$ 1024 بسازیم. برای ماجولها تعداد خطوط آدرس مورد نیاز برابر 8 بیت است $\left(\mathrm{256}\mathrm{\ =\ }{\mathrm{2}}^{\mathrm{8}}\right)$، برای حافظه ساخته شده تعداد خطوط آدرس برابر 10 بیت $\left(\mathrm{1024}\mathrm{\ =\ }{\mathrm{2}}^{\mathrm{10}}\right)$ است.
بنابراین از این 10 خط آدرس، 8 خط به آدرس ماجولهای حافظه متصل میشود و 2 خط آدرس باقیمانده خروجی یکی از ماجولهای حافظه را به خروجی اصلی هدایت میکند. اگر خطوط رتبه پایین به خطوط آدرس متصل شود و انتخاب توسط خطوط رتبه بالا انجام شود به آن برگ برگسازی رتبه بالا (High order Interleaving) میگویند و اگر انتخاب توسط خطوط رتبه پایین انجام شود به آن برگ برگسازی رتبه پایین (Low order Interleaving) میگویند.
شکل زیر برگ برگسازی حافظه را نشان میدهد.

مزیت اصلی روش Low Order این است که میتوان در هر لحظه چهار دسترسی همزمان (تقریباً همزمان) به حافظه داشت، بنابراین سرعت حافظه تقریباً 4 برابر میشود.
منابع
-
https://www.enterprisestorageforum.com/hardware/types-of-computer-memory/#What_are_the_Different_Types_of_Computer_Memory
- https://www.konkurcomputer.ir/%D8%A2%D9%85%D9%88%D8%B2%D8%B4-%D9%85%D8%B9%D9%85%D8%A7%D8%B1%DB%8C-%DA%A9%D8%A7%D9%85%D9%BE%DB%8C%D9%88%D8%AA%D8%B1.html
- https://www.konkurcomputer.ir/%D8%AA%D8%B3%D8%AA-%D9%85%D8%B9%D9%85%D8%A7%D8%B1%DB%8C-%DA%A9%D8%A7%D9%85%D9%BE%DB%8C%D9%88%D8%AA%D8%B1.html
حافظه RAM و حافظه ROM چیست؟
حافظههای با دسترسی تصادفی به دو دسته حافظه فقط خواندنی (Real Only Memory (ROM)) و حافظه خواندنی/نوشتنی (Read/Write Memory (RWM)) تقسیم میشوند. در ROM دادهها از قبل در آن ذخیره شده و تنها میتوان آن دادهها را خواند و نمیتوان تغییری در آن ایجاد کرد اما در حافظه RAM علاوه بر امکان خواندن داده از حافظه، امکان نوشتن داده در حافظه نیز وجود دارد. شما میتوانید به طور کامل دربارهی این دو حافظه در این مقاله مطالعه کنید
حافظه کش (Cache) چیست؟
به منظور افزایش سرعت دسترسی CPU کامپیوتر به حافظه از نوع دیگری از حافظه به نام کش (Cache) استفاده میکنند که سرعت دسترسی به آن نسبت به RAM بالاتر بوده و باعث افزایش سرعت اجرای برنامهها میشود. در این مقاله، کلیه اطلاعات لازم در خصوص حافظه کش آورده شده است.
انواع حافظه کدامند؟
حافظهها را از نظر اندازه، ظرفیت، سرعت و ... میتوان در دسته بندیهای زیادی قرار داد اما مهمترین آنها دسته بندی از نظر ظرفیت و سرعت حافظه است که برای ما مهمتر است. از این نظر میتوان حافظهها را به دو دسته اصلی و ثانویه تقسیم بندی کرد که هر کدام عملکرد متفاوتی دارند. در این مقاله سعی شده این دسته بندی، تفاوتها و مزایای هر کدام به طور کامل شرح داده شود.

































