
برای شروع حرفهای کنکور ارشد کامپیوتر،آیتی و علوم کامپیوتر حتما روی عکس زیر کلیک کنید تا در کانال کنکور کامپیوتر عضو شوید، در این کانال به معرفی بهترین منابع کنکور ارشد،برنامه ریزی و مشاوره، معرفی گرایشها و هر آنچه برای موفقیت در کنکور ارشد نیاز دارید پرداخته شده است

یک خط تولید کارخانهی خودرو سازی را که نمونهی آن در شکل زیر آمده است، در نظر بگیرید.
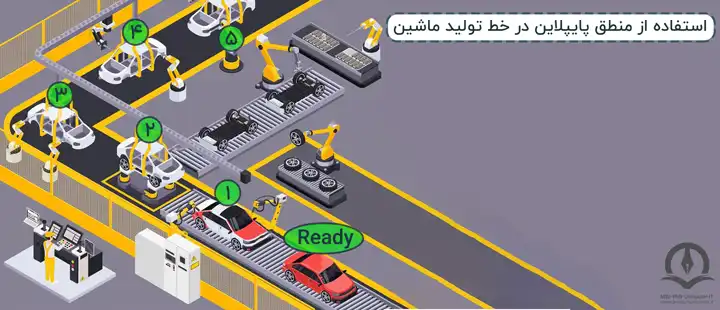
همانطور که از شکل بالا مشخص است، برای تولید یک خودرو نیاز است چندین مرحله طی شود: طراحی و ساخت بدنهی خودرو، افزودن چرخها، رنگ کردن بدنه خودرو و غیره. اما نکته مهم در این خط تولید این است که اگر ماشینی در مرحلهی رنگ شدن بدنهی خود باشد (ماشین شماره 1)، به ماشین پشت سرش چرخ اضافه میشود (ماشین شماره 2) و همینطور ماشین پشت آن دو (ماشین شماره 3)، در قسمت ساخت و بررسی بدنه قرار دارد و به همین شکل تا آخر. اگر در شکل بالا فرض کنیم از زمانی که بدنه اولین خودرو شروع به ساخته شدن کند تا زمانی که همان خودرو کاملا آماده و تولید شود، 10 واحد زمانی (مثلا 10 ساعت) طول بکشد و همچنین خط تولید ما دارای 10 مرحله باشد که هر مرحله 1 ساعت طول بکشد، خودروی بعدی در ساعت 11ام آماده میشود و همینطور خودروی سوم در ساعت 12ام و الی آخر؛ یعنی از زمانی که خودرو اول کاملا تولید شد، چون پشت سرش خط تولید در حال کار کردن است، یک ساعت بعد خودروی بعدی حاضر میشود، گویی کارخانه از ساعت 10ام به بعد در هر ساعت یک خوردو تولید میکند! اما آیا واقعا ساخت هر خودرو یک ساعت زمان میبرد؟ قطعا پاسخ به این سوال منفی است. علت این امر این است که خط تولید کارخانه متوالیا و پست سر هم در حال طی شدن است، درست مانند شکل بالا. حال چه میشد اگر کارخانه به جای استفاده از این ترفند به این صورت عمل کند که تا زمانی که یک خودرو کاملا ساخته نشده، اقدام به ساخت خودروی دیگری نکند؟ در این صورت پس از 10 ساعت که یک خودرو ساخته شد باید مجدد و از ابتدا اقدام به تولید خودروی دوم کند و این یعنی در ساعت 20ام تازه این کارخانه توانسته خودروی دوم خود را تولید کند! در حالی که در رویکرد قبلی (آنچه در شکل آمده است) در ساعت 11ام دومین خودرو ساخته شد.
این رویکرد دقیقا همان روشی است که پردازنده (CPU) برای انجام دستورات برنامه، به منظور افزایش کارایی و سرعت انجام دستورات، از آن استفاده میکند. یعنی به جای اینکه صبر کند یک دستوری از مرحله فراخوانی از حافظه (Fetch) تا زمان اجرا (Execution) کاملا طی شود سپس دستور بعدی را فراخوانی کند، از همین روش استفاده کرده و پس از اینکه دستور اول از مرحله Fetch وارد مرحله رمزگشایی (Decode) میشود، دستور دوم وارد مرحله Fetch میشود و این روند دقیقا همانند خط تولید خودرو ادامه میابد. اصطلاحاً میگوییم در این روش پردازنده از پایپلاین یا خط لوله استفاده کرده که این روش خود یک فصل از درس معماری کامپیوتر آموزش جامع معماری کامپیوتر در مهندسی کامپیوتر، معماری کامپیوتر مجموعهای از قوانین و روشهایی است که به چگونگی طراحی، کارکرد، سازماندهی و پیاده سازی (ساخت) سیستمهای کامپیوتری میپردازد، در این صفحه به بررسی و آموزش کامل معماری کامپیوتر پرداخته شده است محسوب میشود که در آنجا بیشتر به آن پرداخته میشود. در قسمتهای بعد این مقاله مفصلاً این روش را شرح خواهیم داد.
در مهندسی کامپیوتر، معماری کامپیوتر مجموعهای از قوانین و روشهایی است که به چگونگی طراحی، کارکرد، سازماندهی و پیاده سازی (ساخت) سیستمهای کامپیوتری میپردازد، در این صفحه به بررسی و آموزش کامل معماری کامپیوتر پرداخته شده است محسوب میشود که در آنجا بیشتر به آن پرداخته میشود. در قسمتهای بعد این مقاله مفصلاً این روش را شرح خواهیم داد.
پایپلاین یا خط لوله (Pipeline) چیست؟
یک راه برای اجرای دستورات در پردازنده استفاده از روش پایپلاین است که در آن تلاش میشود تا با همپوشانی بین مراحل مختلف اجرای دستورات، به تسریع دست پیدا کنیم. بهتر است به منظور واضحتر شدن موضوع و آشنایی دقیق با Pipleline آن را با پرداختن به مثالی که در قسمت ابتدایی مقاله دربارهی CPU بیان کردیم، به صورت جزییتر توضیح دهیم.
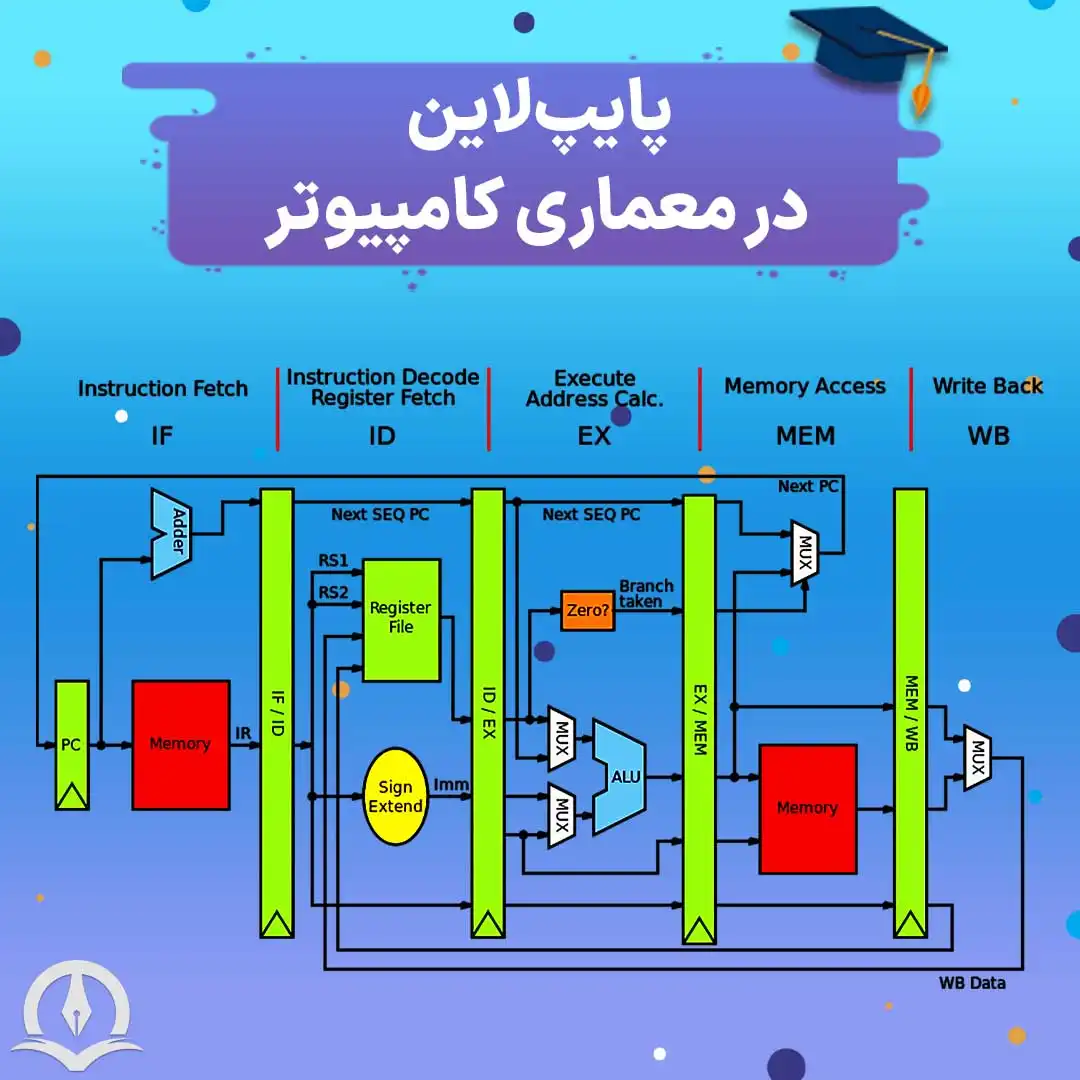
فرض کنید در پردازندهای به شکل زیر عملیات اجرای دستور در 5 مرحله انجام شود. این پنج مرحله عبارتند از: IF، ID، EX، MEM و WB.
شکل ۱: پردازندهی ماشين MIPS
اگر فرض کنیم تأخیر این مراحل به ترتیب 2، 1، 2، 2 و 1 نانوثانیه باشد، طولانیترین زمان اجرای یک دستور برابر مجموع تأخیر این مراحل یعنی 8 نانوثانيه است. برای مثال زمان اجرای یک برنامه نمونه با سه دستور برابر است با: 24 = 8 × 3.
شکل ۲
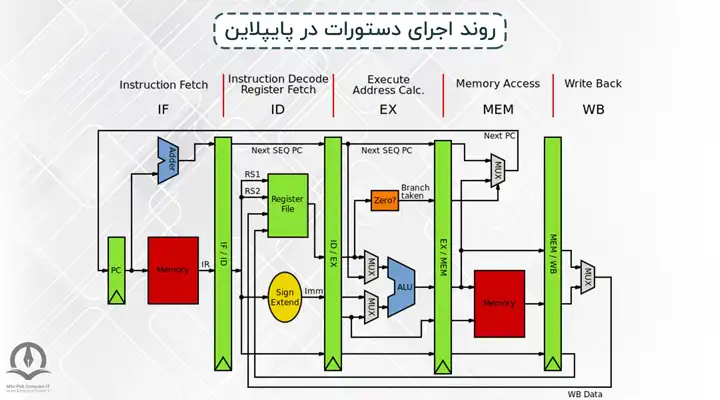
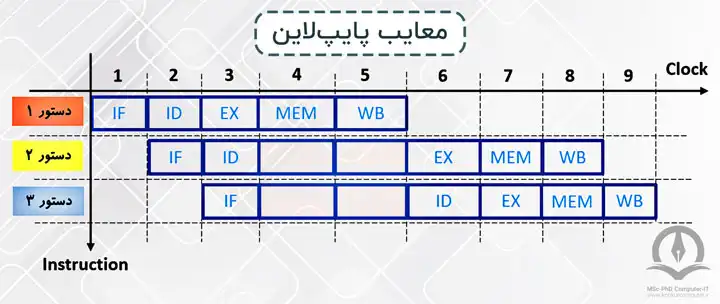
در اینجا، همانطور که در شکل بالا نیز مشخص است، تا زمانی که دستور اول خاتمه نیافته است، دستور دوم شروع نمیشود. احتمالا متوجه شدهاید که ایرادی که به این روش وارد است این است که زمانی که دستور اول از مرحله IF به سطح بعدی (ID) میرود، سطح اول یعنی IF خالی و بیکار میماند و یا وقتی دستور اول در سطح WB قرار میگیرد، 4 سطح قبلی این پردازنده بیکار هستند. این امر سربار زمانی زیادی را به وجود میآورد و باعث میشود توان عملیاتی پردازنده به مقدار نسبتا زیادی افت کند. همانطور که در ابتدا گفته شد یک راه برای اجرای این دستورات در پردازنده استفاده از روش پایپلاین است که در آن تلاش میشود تا با همپوشانی بین مراحل مختلف اجرای دستورات به تسریع دست پیدا کنیم. به شکل زیر توجه کنید:
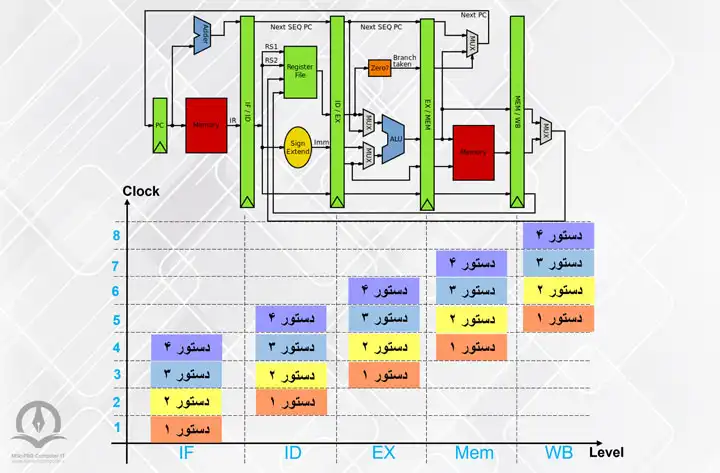
شکل 3
همانطور که در شکل 3 مشاهده میکنید در این روش که از پایپلاین استفاده شده، زمانی که دستور اول از مرحله IF به سطح دوم (ID) میرود، دستور دوم وارد سطح IF خواهد شد و یا زمانی که دستور اول در مرحله MEM قرار میگیرد، دستور اول در سطح قبلی آن یعنی سطح EX، دستور سوم در سطح ID و دستور چهارم در سطح IF قرار میگیرند. این امر موجب میشود در هیچ لحظهای هیچ یک از سطوح پردازنده بیکار نماند؛ در نتیجه تعداد دستورات انجام شده در واحد زمان (توان عملیاتی) توسط این پردازنده افزایش خواهد یافت.
نکته مهم در استفاده از پایپلاین این است که عملا تاخیر سطوح مختلف پردازنده باهم برابر نخواهند بود (همانطور که طبق مثال گفته شده برای شکل ۲ تاخیرها متفاوت بودند) در نتیجه به عنوان مثال وقتی دستور اول در سطح EX قرار میگیرد – که تاخیرش 2نانوثانیه است (طبق فرض قبل) - دستور دوم در سطح ID قرار دارد که پس از 1نانوثانیه کارش تمام شده و وارد سطح EX میشود. این درحالی است که دستور اول هنوز کارش تمام نشده در نتیجه بین این دستورات تداخل پیش میآید. در این مورد راهکار پیشنهادی این است که با قرار دادن ثباتها بین این سطوح از مدارات، مشکل گفته شده را حل میکنند؛ به این صورت که هر سطحی که کارش تمام شد مقدار خروجی خود را نگه داشته تا پس از اعمال کلاک، آن مقدار را با استفاده از ثباتها وارد سطح بعد کند. مقدار کلاک را برابر با جمع تاخیر یک ثبات با بیشترین تاخیر سطوح پردازنده در نظر میگیرند تا هیچگاه مشکل ذکر شده رخ ندهد:
\[{\mathrm{T}}_{\mathrm{clk}}\mathrm{=}{\mathrm{max} \left\{{\mathrm{t}}_{\mathrm{IF}}\mathrm{\ ,\ }{\mathrm{t}}_{\mathrm{ID}}\mathrm{\ ,\ }{\mathrm{t}}_{\mathrm{EX}}\mathrm{\ ,\ }{\mathrm{t}}_{\mathrm{MEM}}\mathrm{\ ,\ }{\mathrm{t}}_{\mathrm{WB}}\right\}\ }\mathrm{+\ }{\mathrm{t}}_{\mathrm{Register}}\]
برای مثال اگر از زمان تاخیر ثباتها چشم پوشی کنیم، مقدار کلاک طبق فرض گفته شده برابر است با:
\[{\mathrm{T}}_{\mathrm{clk}}\mathrm{=}{\mathrm{max} \left\{\mathrm{2\ ,\ 1\ ,\ 2\ ,\ 2\ ,\ 1}\right\}\ }\mathrm{=2ns}\]
محاسبه زمان اجرای دستورات در پایپلاین
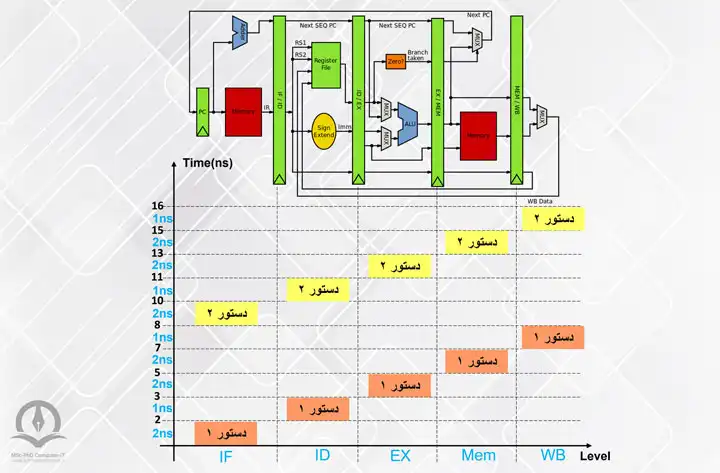
همانطور که در شکل 3 میبینید، دستور اول کلیه سطوح را در 5 کلاک میپیماید و در کلاک بعد (کلاک 6 ام) دستور دوم، در کلاک 7 ام دستور سوم، در کلاک 8 ام دستور چهارم و ... انجام میشوند. گویی پس از انجام دستور اول، دستورات بعدی هر یک پس از یک پالس ساعت انجام میشوند. در نتیجه اگر n دستور را بخواهیم در پردازندهی دارای پایپلاین K سطحی پردازش کنیم، زمان لازم جهت پردازش این n دستور به صورت زیر محاسبه میشود:
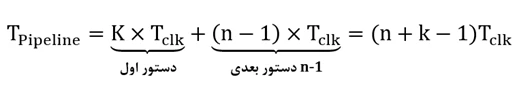
مطابق فرض قبل زمان اجرای سه دستور در پیادهسازی پایپلاین برابر است با: 5x2 + (3 - 1) x 2 = 14ns
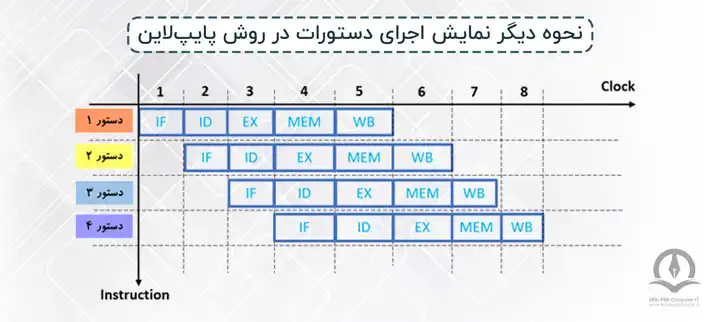
شکل ۴: نحوه دیگر نمایش اجرای دستورات در روش پایپلاین
کاربرد پایپلاین
بهطورکلی خط لوله یا پایپلاین باعث افزایش توان عملیاتی کلی میشود. در سیستم خط لوله، رجیستر برای نگهداری دادهها استفاده میشود و مدارهای منطقیآموزش مدار منطقی به زبان ساده - بررسی مدار منطقی و انواع آن امروزه درک صحیحی از مدارهای منطقی برای هر مهندس برق و کامپیوتر ضروری است. این مدارها عنصر اصلی کامپیوترها و بسیاری از وسایل الکترونیکی اطراف ما هستند، در این صفحه به بررسی و آموزش مدار منطقی پرداخته شده است واقع در هر بخش بر روی آن عملیات انجام میدهند. خروجی مدار ترکیبی به رجیستر ورودی قطعه بعدی اعمال میشود.
امروزه درک صحیحی از مدارهای منطقی برای هر مهندس برق و کامپیوتر ضروری است. این مدارها عنصر اصلی کامپیوترها و بسیاری از وسایل الکترونیکی اطراف ما هستند، در این صفحه به بررسی و آموزش مدار منطقی پرداخته شده است واقع در هر بخش بر روی آن عملیات انجام میدهند. خروجی مدار ترکیبی به رجیستر ورودی قطعه بعدی اعمال میشود.
سیستم خط لوله مانند راهاندازی خط مونتاژ امروزی در کارخانههای مدرن است. بهعنوان مثال در یک صنعت خودروسازی، خطوط مونتاژ عظیمی راه اندازی میشود و در هر نقطه، بازوهای رباتیک برای انجام یک کار خاص وجود دارد و سپس ماشین به حرکت در میآید و به سوی بازوی بعدی حرکت میکند.
Latency و Throughput به چه معنی هستند؟
مدت زمانی که طول میکشد تا اطلاعات از ورودی به خروجی برسد را Latency میگوییم، همچنین لازم به ذکر است که به تعداد دستورات پردازش شده در واحد زمان Throughput گفته میشود.
بهعنوان مثال فرض کنید که برای یک لوله آب یک ثانیه طول میکشد تا یک مولکول آب از ابتدا به انتهای آن برسد که این مفهوم همان Latency است. از طرفی میدانیم که در هر ثانیه ده مولکول آب از لوله خارج میشود که این همان مفهوم Throughout را به ما منتقل میکند. احتمالاً به این نکته توجه کردهاید که وقتی میخواهیم در خروجی لوله مولکولهای آب را ببینیم، برای اولین بار نیاز است تا به اندازه زمان Latency صبرکنیم تا در خروجی لوله بتوانیم مولکول آب را مشاهده کنیم، اما پس از آن میتوان با زمان بسیار کمتری مولکولهای آب را در خروجی مشاهده کرد چرا که قبل از اینکه مولکول آب بعدی بخواهد به خروجی برسد مولکول دیگری به لوله وارد خواهد شد. این دقیقاً همان کاربرد و مفهوم پایپ لاین برای اطلاعات و دادههاست.
انواع پایپ لاین:
پایپلاین انواع مختلفی دارد که در این مقاله تنها به معرفی آنها میپردازیم:
- Arithmetic Pipelining
- Instruction Pipelining
- Processor Pipelining
- Unifunction Vs. Multifunction Pipelining
- Static vs Dynamic Pipelining
- Scalar vs Vector Pipelining
مخاطره در پایپلاین:
زمانی که عملکرد پایپلاین به درستی صورت نگیرد، میگوییم مخاطره رخ داده است. به عبارت دیگر اگر نتوان در سیکل ساعت بعدی دستور جدیدی وارد پایپلاین کرد میگوییم پایپلاین دچار مخاطره (Hazard) شده است. انواع مخاطرهها عبارتند از مخاطره ساختاری (Structural Hazard)، مخاطره دادهای (Data Hazard) و مخاطره کنترلی (Control Hazard).
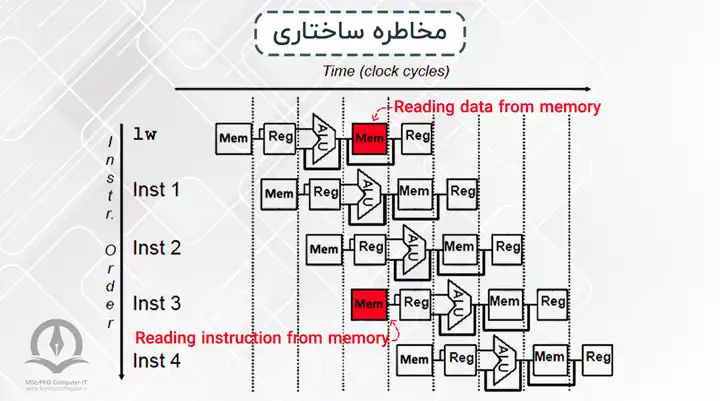
مخاطره ساختاری
در اینجا به دلیل محدودیت منابع نمیتوان در سیکل بعدی دستور جدیدی وارد پایپلاین کرد. برای مثال فرض کنید در پیادهسازی پایپلاین پردازنده MIPS حافظه داده و دستور یکی باشند. در این صورت در بعضی از سیکلهای ساعت به دلیل دسترسی به حافظه توسط یک دستور، دستور دیگر نمیتواند واکشی شود.
مخاطره دادهای
در اینجا به دلیل وابستگی دادهای بین دستورات نمیتوان در سیکل بعدی دستور جدیدی وارد پایپلاین کرد. برای مثال در مجموعه دستورات زیر، دستور add در رجیستر R2 مینویسد و دستور sub از رجیستر R2 استفاده میکند. در نتیجه تا زمانی که دستور اول محتویات رجیستر R2 را تغییر نداده است، دستور دوم نمیتواند محتویات رجیستر R2 را بخواند.
ADD R2, R3, R5
SUB R7, R2, R4
برای حل این مشکل از یک روش به نام Data Forwarding استفاده میکنیم که در آن یک کپی از دادهای که قرار است در رجیستر R2 نوشته شده را به دستور بعدی میدهیم تا بتواند به اجرای خود ادامه دهد.
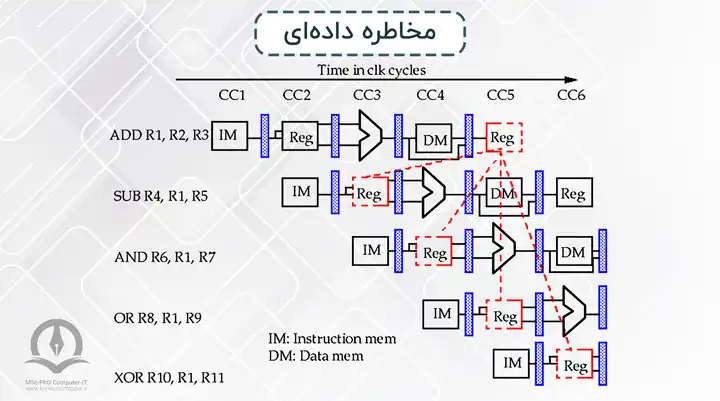
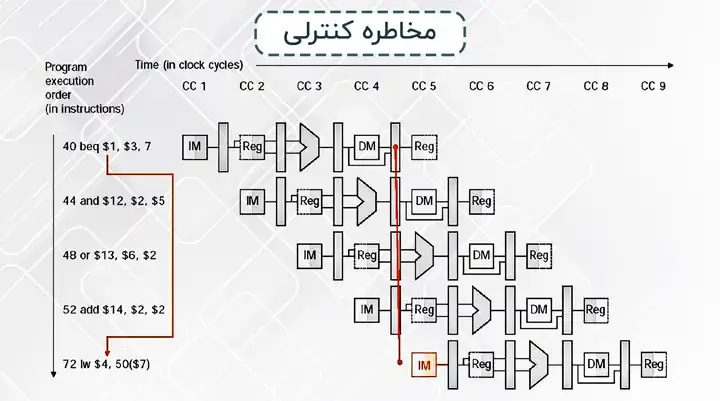
مخاطره کنترلی
در اینجا به دلیل وجود یک دستور پرش شرطی، دستور بعدی که باید وارد پایپلاین شود مشخص نیست. برای مثال در مجموعه دستورات زیر، اگر شرط پرش برقرار نباشد، دستور add وارد پایپلاین میشود و اگر شرط پرش برقرار باشد، دستور sub وارد پایپلاین میشود. بنابراین باید منتظر بمانیم تا وضعیت شرط پرش مشخص شود تا بتوانیم دستور صحیح را وارد پایپلاین کنیم.
BEQ R2, R3, L1
ADD R2, R3, R5
...
L1: SUB R7, R2, R4
یکی از راهکارها برای حل این مشکل این است که میتوان همیشه فرض کرد که شرط پرش برقرار نیست و دستور بعدی را وارد پایپلاین کنیم، اگر در ادامه مشخص شد فرض ما درست است که دستور به صورت عادی در پایپلاین اجرا میشود. ولی اگر مشخص شد که فرض اولیه ما نادرست است باید دستوری که به اشتباه وارد پایپلاین شده است را از پایپلاین بیرون کنیم و دستور درست را وارد پایپلاین کنیم.
مزایا و معایب پایپ لاین:
مزایای Pipeline :
چرخه زمانی پردازنده کاهش مییابد
افزایش توان عملیاتی خط لوله زمان لازم برای تکمیل یک دستورالعمل را کاهش نمیدهد. در عوض، تعداد دستورالعملهایی را که میتوان در واحد زمان پردازش کرد، افزایش میدهد و تأخیر بین دستورالعملهای تکمیلشده را کاهش میدهد. هرچه یک پردازنده مراحل پایپ لاین بیشتری داشته باشد، دستورات بیشتری را میتواند پردازش کند و تأخیر بین دستورالعملهای تکمیلشده کمتر است. هر ریزپردازنده که امروزه تولید میشود، حداقل از ۲ مرحله خط لوله تا ۳۰ یا ۴۰ مرحله استفاده میکند.
باعث افزایش توان عملیاتی سیستم میشود
در صورت استفاده از خط لوله، واحد منطقی محاسباتی CPU میتواند سریعتر، اما پیچیدهتر طراحی شود. استفاده از خط لوله به صورت تئوری، میزان عملکرد روی یک هسته پردازنده را نسبت به حالت بدون خط لوله، با ضریب تعداد مراحل تسریع میبخشد.
\[\mathrm{SpeedUp\ =\ }\frac{{\mathrm{T}}_{\mathrm{S.C.}}}{{\mathrm{T}}_{\mathrm{Pipeline}}}=\frac{\mathrm{nkt}}{\mathrm{kt\ +\ }\left(\mathrm{n}\mathrm{-}\mathrm{1}\right)\mathrm{t}}=\frac{\mathrm{nk}}{\mathrm{n\ +\ k}\mathrm{-}\mathrm{1}}{{\mathop{\longrightarrow}\limits_{\mathrm{\ \ \ n\ }\mathrm{\to }\mathrm{\ +}\mathrm{\infty }\mathrm{\ \ \ }}}}\ \mathrm{k}\]
باعث اطمینان سیستم میشود
CPUهای دارای پایپلاین معمولاً در فرکانس ساعت بالاتر از فرکانس ساعت RAM کار میکنند که باعث افزایش عملکرد کلی رایانهها میشود.
معایب Pipeline:
- طراحی یک پردازنده بدون پایپلاین از نظر ساخت و پیاده سازی، سادهتر و ارزانتر است، پردازندههای غیر لولهای تنها یک دستور را در یک زمان اجرا میکند.
- در پردازندههای خط لولهای، قراردادن ثباتها (رجیسترها) بین ماژولها باعث افزایش تأخیر دستورالعملها در مقایسه با یک پردازنده غیر لولهای میشود.
- یک پردازنده بدون پایپلاین دارای یک توان عملیاتی تعریف شده خواهد بود. پیشبینی عملکرد یک پردازنده دارای خط لوله دشوارتر است و ممکن است برای برنامههای مختلف بسیار متفاوت باشد.
- بسیاری از پردازندهها شامل پایپلاینایی با تعداد سطوح 7، 10، 20، 31 و حتی بیشتر هستند. نقطه ضعف خط لوله طولانی این است که وقتی یک برنامه دارای دستورات انشعاب (پرش) است، کلیه سطوح پایپلاین تا قبل از آن دستور انشعاب باید خالی شود. در نتیجه زمانی که کد اجرا شده دارای شاخههای زیادی باشد، توان عملیاتی پردازنده کاهش مییابد زیرا پردازنده از قبل نمیداند که دستورالعمل بعدی در کجا قرار دارد، و باید منتظر بماند تا دستورالعمل انشعاب به پایان برسد و همچنین سطوح پایپلاین تا قبل از آن دستور انشعاب باید خالی بماند. این نقطه ضعف را میتوان با پیشبینی (بر اساس فعالیت و تجارب قبلی) اینکه آیا آن دستورالعمل شرطی منشعب میشود یا خیر، کاهش داد. پس از اینکه انشعاب حل شد، دستورالعمل بعدی باید تمام مسیر را از طریق خط لوله طی کند تا نتیجه آن در دسترس باشد و پردازنده دوباره کار را از سر بگیرد.
- در یک برنامه همه دستورالعملها مستقل نیستند. در یک خط لوله ساده، تکمیل یک دستورالعمل ممکن است به 5 مرحله نیاز داشته باشد. به عنوان مثال زمانی که 5 دستور بخواهند در پردازنده اجرا شوند، برای کارکرد درست پایپلاین، این خط لوله باید 4 دستورالعمل مستقل بعدی را در حالی که اولین دستور در حال تکمیل است اجرا کند. اما هر یک از این 4 دستورالعمل ممکن است به خروجی اولین دستورالعمل بستگی داشته باشند که باعث میشود منطق کنترل خط لوله منتظر بماند و چندین دستور NoOp (دستوراتی که هیچ کاری انجام نمیدهند) را تا زمانی که وابستگی برطرف شود، در خط لوله وارد کند. خوشبختانه، تکنیکهایی مانند فوروارد کردن (Forwarding) میتواند مواردی را که به توقف نیاز است به میزان قابلتوجهی کاهش دهد.
جمع بندی
Pipelining اجرای دستورات متعدد را به طور همزمان سازماندهی میکند و همچنین باعث بهبود توان عملیاتی سیستم میشود. لازم به ذکر است که اطلاعات و دانش ذکر شده در خصوص تکنیک پایپلاین محدود به این مقاله نشده و این مبحث دارای فصول جداگانهای در دروس معماری کامپیوتر و معماری کامپیوتر پیشرفته است که به جزئیات به بررسی پردازندههای دارای پایپلاین میپردازد که در این رابطه دانشجویان علاقه مند میتوانند با یادگیری درس معماری کامپیوتر به روش صحیح، از این مطالب آگاه شده و در کار خود استفاده کنند.

































